
美团 Java 面试
美团 Java 面试
最近有一些之 前在美团实习同学,跟我反馈在美团转正成功了,跟去年类似,只要在美团实习 60 天左右,就能拿到转正机会,而且转正大概率还是比较大的。
去年的美团普通档的校招薪资都有 35w 年薪,所以能转正成功,还是非常不错,而且秋招也相比实习的时候会更卷一点,因为秋招是一个大规模的求职招聘,竞争的人也相对更多一些。
当然,如果运气不好,没有转正成功的同学,也不 必灰心,你已经有一段大厂的实习经历了,在秋招也是会有很大优势的。
这次,来跟大家分享一位同学的美团后端开发面经,同学反馈是他参加秋招一来压力最大的一场面试,这个压力大倒不是说问题特别多和难,主要是问法都比较场景化。
一上来主要问了几个常规的八股,后面主要是问了一些非「常规」的八股文。
主要是自己准备的不够充分,面对一些比较场景化的面试题就比较慌张了,最后还是讲出了自己的一些想法,面完 20 分钟之后,收到电话通知幸运的通关了一面。

常规八股
HTTP 常见状态码有哪些?

HTTP 状态码分为 5 大类
1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
2xx 类状态码表示服务器成功处理了客户端的请求,也是我们最愿意 看到的状态。
3xx 类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资
源,也就是重定向。
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错
误码。
其中常见的具体状态码有:
200 :请求成功;
301 :永久重定向;302 :临时重定向;
404 :无法找到此页面;405 :请求的方法类型不支持;
500 :服务器内部出错。
MySQL 事务特性是什么 ?怎么实现的?
原子性(Atomicity ):一个事 务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节,而且事 务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事 务从来没有执行过一样,就好比买一件商品,购买成功时,则给商家付了 钱,商品到手;购买失败时,则商品在商家手中,消费者的钱也没花出去。
一致性(Consistency ):是指事务操作前和操作后,数据满足完整性约束,数据库保持一致性状态。比如,用户 A 和用户 B 在银行分别 有 800 元和 600 元,总共 1400 元,用户 A 给用户 B转账 200 元,分为两个 步骤,从 A 的账户扣除 200 元和对 B 的账户增加 200 元。一致性就是 要求上述步骤操作后,最后的结果是用户 A 还有 600 元,用户 B 有 800 元,总共 1400 元,而不会出现用户 A 扣除了 200 元,但用户 B 未增加的情况(该情况,用户 A 和 B 均为 600 元,总共 1200 元)。
隔离性(Isolation ):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事 务并发执行时由于交 叉执行而导致数据的不一致,因为多个事 务同时使用相同的数据时,不会相互干扰,每个事 务都有一个完整的数据空间,对其他并发事务是隔离的。也就是说,消费者购买商品这个事 务,是不影响其他消费者购买的。
持久性(Durability ):事务处理结束后,对数据的修改就是永久的,即便系统故障也不 会丢失。
MySQL InnoDB 引擎通过什么 技术来 保证事务的这四个特性的呢?
持久性是通过 redo log (重做日志)来保证的;
原子性是通过 undo log (回滚日志) 来保证的;
隔离性是通过 MVCC (多版本并发控制) 或锁机制来保证的;
一致性则是通过持久性+原子性+隔离性来保证;
Java 线程池的核心参数有哪些?
线程池是为了 减少频繁的创建线程和销毁线程带来的性能损耗,线程池的工作原理如下图:
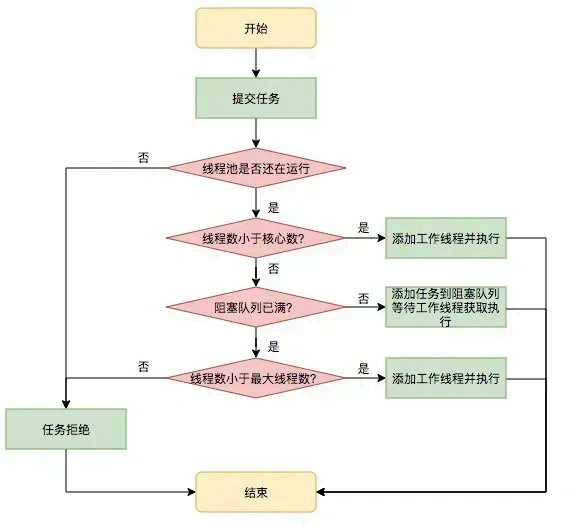
线程池分为核心线程池,线程池的最大容量,还有等待任务的队列,提交一个任务,如果核心线程没有满,就创建一个线程,如果满了,就是会加入等待队列,如果等待队列满了,就会增加线程,如果达到最大线程数量,如果都达到最大线程数量,就会按照一些丢 弃的策略进行处理。
线程池的构造函数有7个参数:
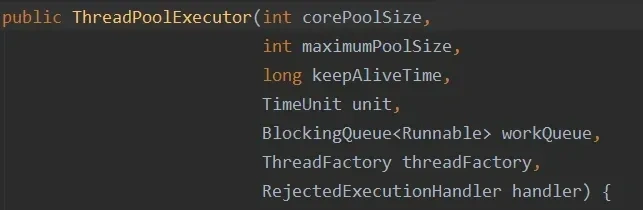
corePoolSize :线程池核心线程数量。默认情况下,线程池中线程的数量如果 <= corePoolSize ,那么即使这些线程处于空闲状态,那也不 会被销毁。
maximumPoolSize :限制了线程池能创建的最大线程总数(包括核心线程和非核心线程),当corePoolSize 已满 并且 尝试将新任务加 入阻塞队列失败(即队列已满)并且 当前线程数 < maximumPoolSize ,就会创建新线程执行此任务,但是当 corePoolSize 满 并且 队列满 并且线程数已达 maximumPoolSize 并且 又有新任务提交时,就会触发拒绝策略。
keepAliveTime :当线程池中线程的数量大于corePoolSize ,并且某个线程的空闲时间超过了keepAliveTime ,那么这个线程就会被销毁。
unit :就是keepAliveTime 时间的单位。
workQueue :工作队列。当没有空闲的线程执行新任务时,该任务就会被放入工作队列中,等待执行。
threadFactory :线程工厂。可以用来给线 程取名字等等
handler :拒绝策略。当一个新任务交给线 程池,如果此时线程池中有空闲的线程,就会直接执行,如果没有空闲的线程,就会将该任务加 入到阻塞队列中,如果阻塞队列满了,就会创建一个新线程,从阻塞队列头部取出一个任务来执行,并将新任务加 入到阻塞队列末尾。如果当前线程池中线程的数量等于maximumPoolSize ,就不会创建新线程,就会去执行拒绝策略
你知道哪些 JVM 的 GC 机制?
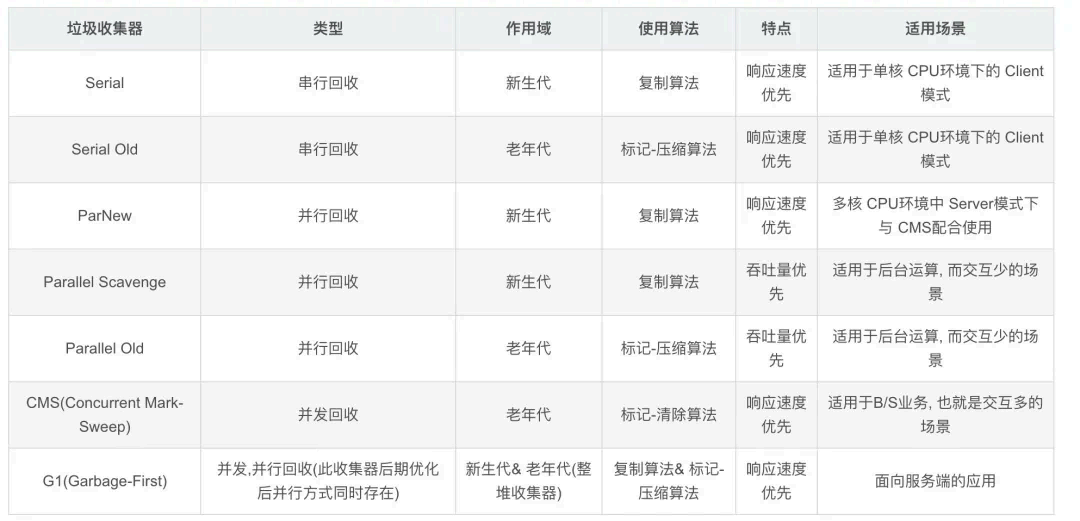
Serial 收集器( 复制算法): 新生代单线程收集器, 标记和清理都是单线程,优点是简单高效;
ParNew 收集器 (复制算法): 新生代收并行集器, 实际上是Serial 收集器的多线程版本,在多核CPU 环境下有着比Serial 更好的表现;
Parallel Scavenge 收集器 (复制算法): 新生代并行收集器, 追求高吞吐 量,高效利用 CPU 。吞吐量 = 用户线程时间/( 用户线程时间+GC 线程时间),高吞吐 量可以高效率的利用CPU 时间,尽快完成程序的运算任务,适合后台 应用等对交互 相应要求不高的场景;
Serial Old 收集器 (标记-整理算法): 老年代单线程收集器, Serial 收集器的老年代版本;
Parallel Old 收集器 (标记-整理算法):老年代并行收集器, 吞吐 量优先,Parallel Scavenge 收集器的老年代版本;
CMS(Concurrent Mark Sweep) 收集器( 标记-清除算法):老年代并行收集器, 以获取最短回收停顿时间为目标的收集器, 具有高并发、低停顿的特点,追求最短GC 回收停顿时间。
G1(Garbage First) 收集器 (标记-整理算法):Java 堆并行收集器, G1 收集器是JDK1.7 提供的一个新收 集器, G1 收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。此外,G1 收集器不同于之 前的收集器的一个重要特点是:G1 回收的范围是整个Java 堆(包括新生代,老年代),而前六种收集器回收的范围仅限于新生代或老年代
非「常规八股」
如果服 务应用部署在 Linux 上,CPU 打满后,想查看哪个进程导致的,用什么 命令?
方式一 , top :这是一个实时监控系统性能的工具。你只需在终端中输入:
top
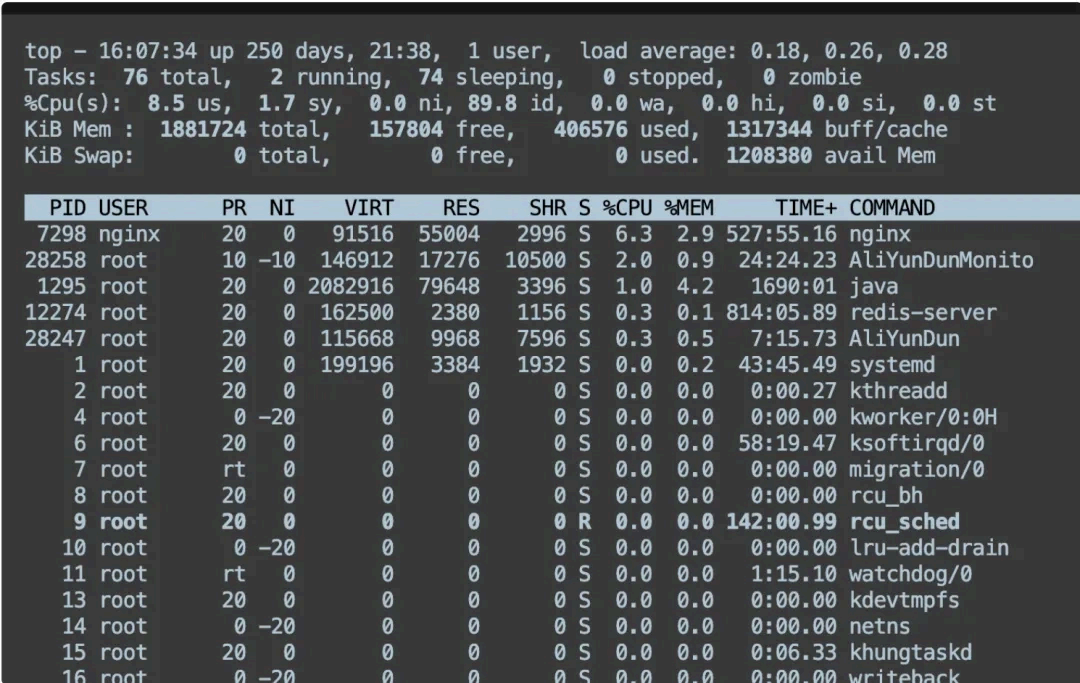
然后可 以按 P 键来按 CPU 使用率排序,查看哪些进程占用了最多的 CPU 资源。
方式二, ps :如果你想查看当前所有进程的 CPU 使用情况,可以使 用:
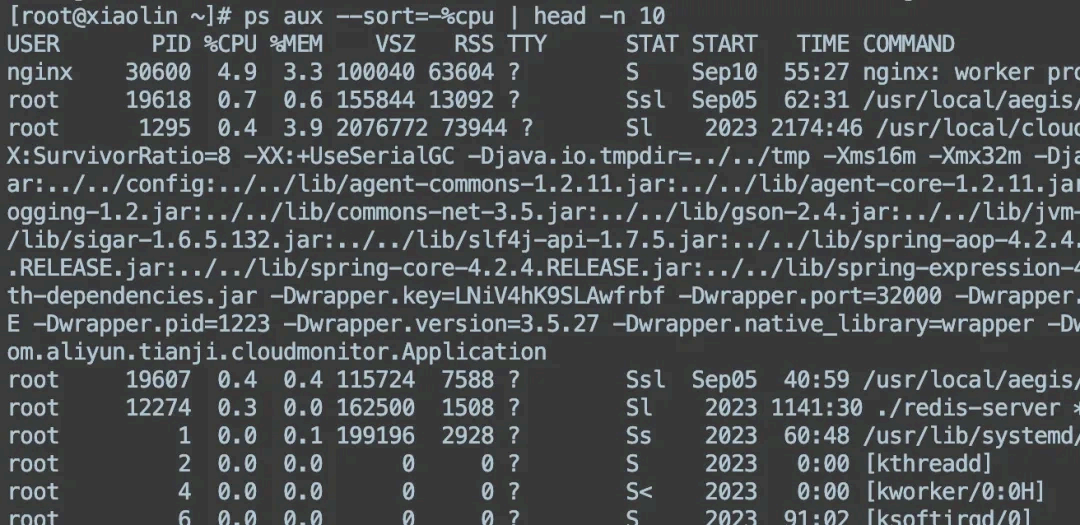
这将显示 CPU 使用率最高的前10 个进程。
方式三,pidstat :如果你需要更详细的信息,可以使 用 pidstat :
pidstat -u 1
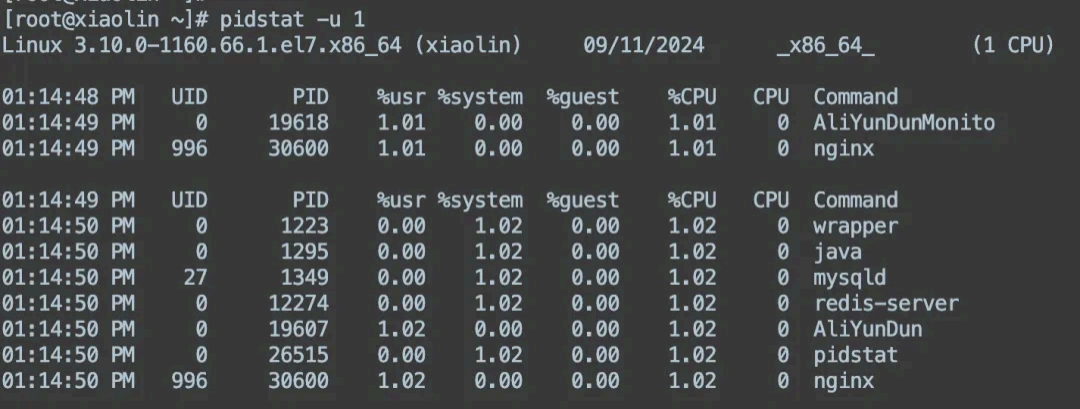
这将每秒显示所有进程的 CPU 使用情况。
如果想查看是进程的哪个线程,用什么 命令?
在 ps 和 top 命令加一下参数,就能看到线程状态了:
ps -eT | grep <进程名或线程名>执行 top -H -p pid ,查看该进程下占用CPU 高的线程id ,比如我们定位到我们的占用CPU 比较高的进程id 为 99770
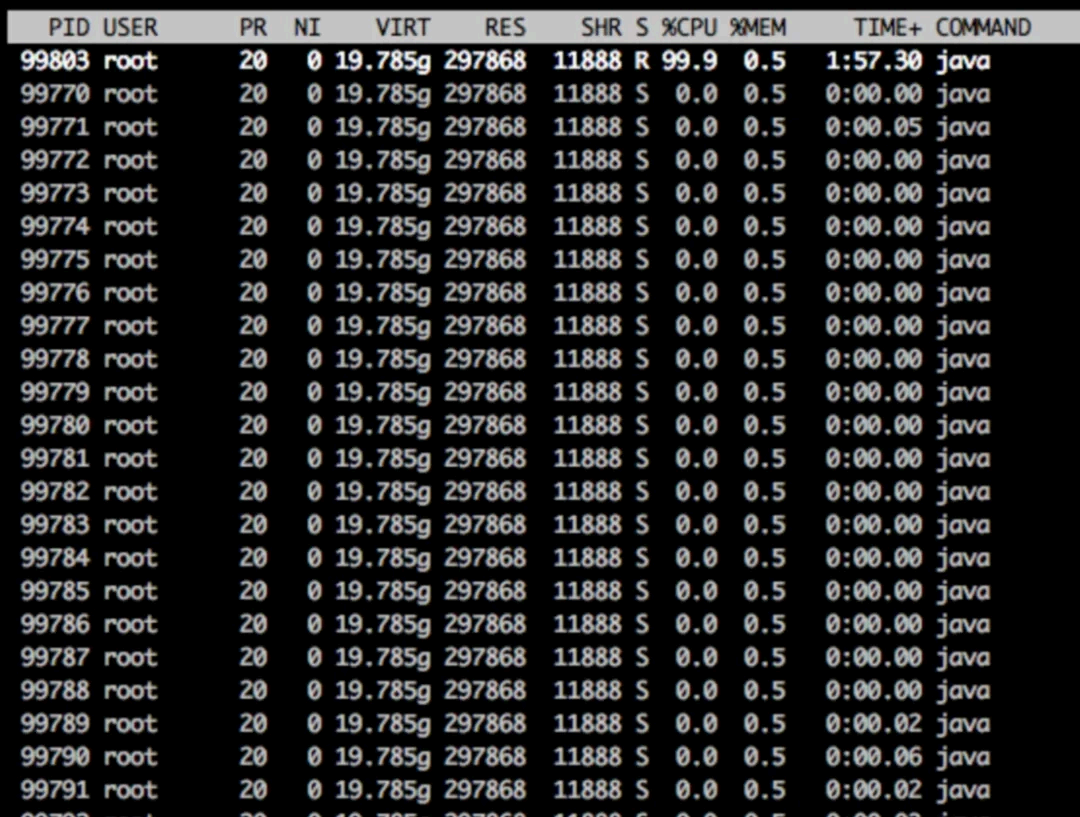
我们会 看pid 为99803 的线程占用CPU 最高,将其转换为16 进制数,为 0x185db
想查看代码中哪个位置导致的 CPU 高,该怎么做?Java 应用怎么排查 CPU
或内存占用率过高的问题?
可以通过 jstack 工具具 体查看线程哪个位置导致 cpu 过高的原因。
- 将线程的 dump 输出到 dump.out 日志文件中
jstack 99770 > dump.out- 查看dump 日志,查找关键字0x185db (线程id 的 16 进制),刚才我 们定位的线程pid 的16 进制表示:
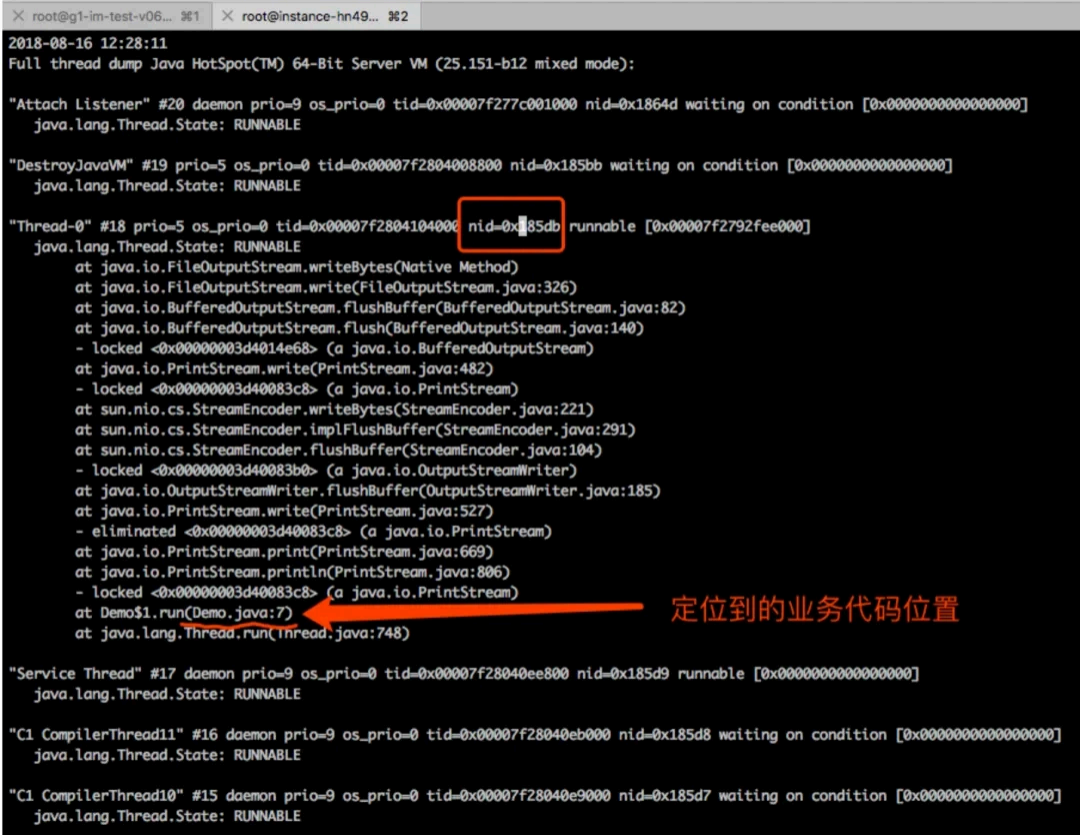
当程序出现故障,往往 一次 dump 的信息,还不足以确认问题。建议最好多 生成几次 dump 信息,比如3次,如果每次 dump 都指向同 一个线程代码,我们才确定问题的典型性。
以上,就是如何使 用jstack 命令查看CPU 使用率高的线程运行日志信息,定位到具体的代码行。
数据库翻页(limit )查询时,发现越往后查询越来越慢,为什么 ?该如何修改 SQL 能解决?
数据库翻页查询时,尤其是使用 LIMIT 查询,有时会出现性能下降的问题。
原因是当使用limit x, y 时,数据库必须跳过 x 数量的行,这意味着它可能需要完全扫描前面的行,从而导致查询变慢,比如 limit 1000,10 ,查询方式就是从第 1条记录扫描到第 1000 条记录之后,往右边取 10 条记录返回,然后抛弃前面扫描的 1000 条记录。
解决方式,可以考虑使用基于主 键的分页。例如,对于某个表的时间戳或 ID 列,可以这样做:
-- 使用last_seen_id替代OFFSET
SELECT * FROM your_table
WHERE id > last_seen_id
ORDER BY id
LIMIT 10;这种方式避免了 linut x ,y 深分页的问题,只获取相对清晰的上一页最后一个 ID 之后的记录。
Insert 或 Update ,不用两个 语句去 分别判 断,用一条语句实现存在就更新,否则就插入?
在 MySQL 中,可以使 用 INSERT ... ON DUPLICATE KEY UPDATE 语法:
INSERT INTO table_name (id, column1, column2)
VALUES (1, 'value1', 'value2')
ON DUPLICATE KEY UPDATE column1 = VALUES(column1), column2 = VALUES(column2);在这个语句中,如果 id (假设是主键或唯一索引)已经存在,则更新 column1 和 column2 的值;如果 id 不存在,则插入一条新的记录。
算法
无重复字符的最长子串