
米哈游 Java 面试
米哈游 Java 面试
今天来分享一位同学米哈游的面经,投递的岗位是云原生,同学是校招生没有云原生的基础,所以面试没有问云原生的内容,但是都在计算机基础方面的内容,都是经典的面试问题。
不管是面后端开发、客户端开发、测试开发等岗位,计算机基础的内容都逃不开的,包括社招面大厂,即使工作了好几年,也会问考察一些计算机基础的问题,所以同学们一定要好好 掌握 。

这个面试难在的是在算法, 抽五星卡概率,不愧是游戏大厂,出的题目也是游戏背景。
操作系统
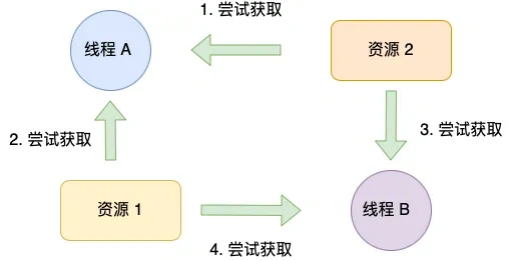
死锁发生条件是什么 ?
死锁只有同时满足以下四个条件才会发生:
互斥条件:互斥条件是指多个线程不能同时使用同一个资源。
持有并等待条件:持有并等待条件是指,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。
不可剥夺条件:不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。
环路等待条件:环路等待条件指的是,在死锁发生的时候,两个 线程获取资源的顺序构成了环形链。
如何避免死锁?
避免死锁问题就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破环环 路等待条件。
那什么 是资源有序分配法呢?线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。
介绍一下操作系统内存管理
操作系统设计 了虚拟内存,每个进程都有自己的独立的虚拟内存,我们所写的程序不会直接与物理内打交道。

有了虚拟内存之后,它带来了这些好处 :
第一,虚拟内存可以使 得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显 的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到 物理内存之外,比如硬盘上的 swap 区域。
第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址 冲突的问题。
第三,页表里的页表项中除了物理地址 之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该 页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
Linux 是通过对内存分页的方式来管理内存,分页是把整个虚拟和物理内存空间切成一段段 固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page )。在 Linux 下,每一页的大小为 4KB 。
虚拟地址 与物理地址 之间通过页表来映射,如下图:
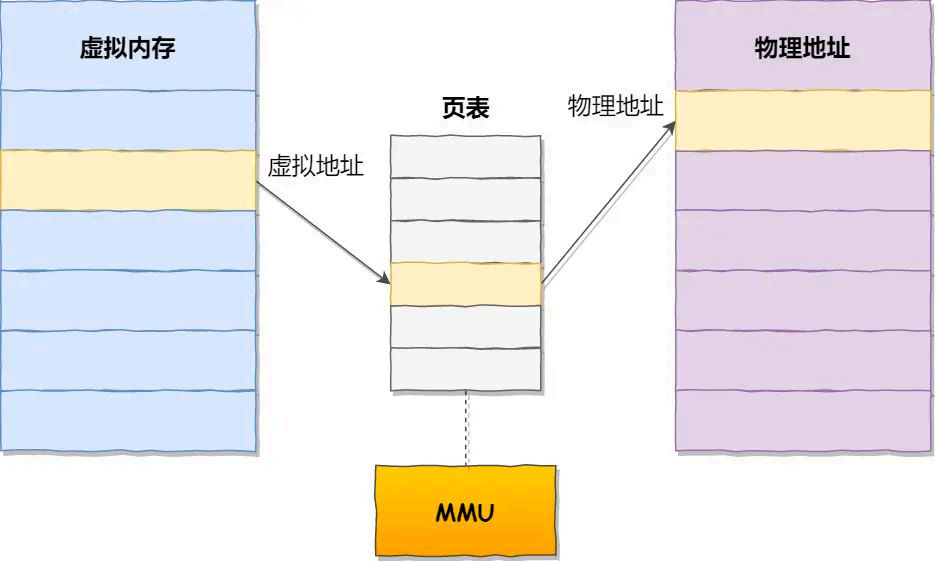
页表是存储在内存里的,内存管理单元 (MMU )就做将虚拟内存地址 转换成物理地址 的工作。
而当进程访问的虚拟地址在 页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
介绍copy on write
主进程在执行 fork 的时候,操作系统会把主进程的「页表」复制一份给子进程,这个页表记录着虚拟地址 和物理地址 映射关系,而不会复制物理内存,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。
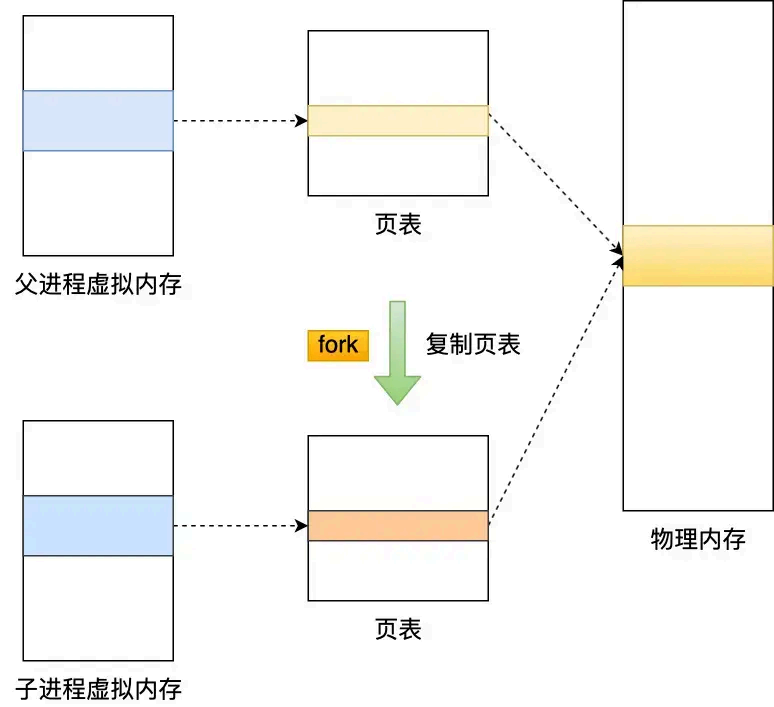
这样一来,子进程就共享了 父进程的物理内存数据了,这样能够节约物理内存资源,页表对应的页表项的属性会标记该 物理内存的权限为只读。
不过,当父进程或者子进程在向这个内存发起写操作时,CPU 就会触发写保护中断,这个写保护中断是由于违反权限导致的,然后操作系统会在「写保护中断处理函数」里进行物理内存的复制,并重新设置其内 存映射关系,将父子进程的内存读写权限设置为可读写,最后才会对内存进行写操作,这个过程被称为「写时复制(Copy On Write )」。
写时复制顾名思义,在发生写操作的时候,操作系统才会去复制物理内存,这样是为了 防止 fork 创建子进程时,由于物理内存数据的复制时间过长而导致父进程长时间阻 塞的问题。
copy on write 节省了什么 资源
节省了物理内存的资源,因为 fork 的时候,子进程不需要复制父进程的物理内存,避免了不 必要的内存复制开销,子进程只需要复制父进程的页表,这时候父子进程的页表指向的都是共享的物 理内存。
只有当父子进程任何 有一方对这片共享的物理内存发生了修改操作,才会触发写时复制机制,这时候才会复制发生修改操作的物理内存。
线程和进程区别
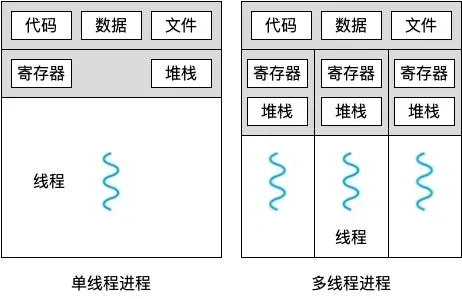
本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位在开销方面:每个进程都有独立的代码和数据空间(程序上下 文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器( PC ),线程之间切换的开销小
稳定性方面:进程中某个线程如果崩溃了,可能会导致整个进程都崩溃。而进程中的子进程崩溃,并不会影响其他进程。
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU 外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
线程切换为什么 比进程切换快,节省了什么 资源?
线程切换比进程切换快是因为线程共享同一进程的地址 空间和资源,线程切换时只需切换堆栈和程序计数器等少量信息,而不需要切换地址 空间,避免了进程切换时需要切换内存映射表等大量资源的开销,从而节省了时间和系统资源。
linux 如何查看进程状态?
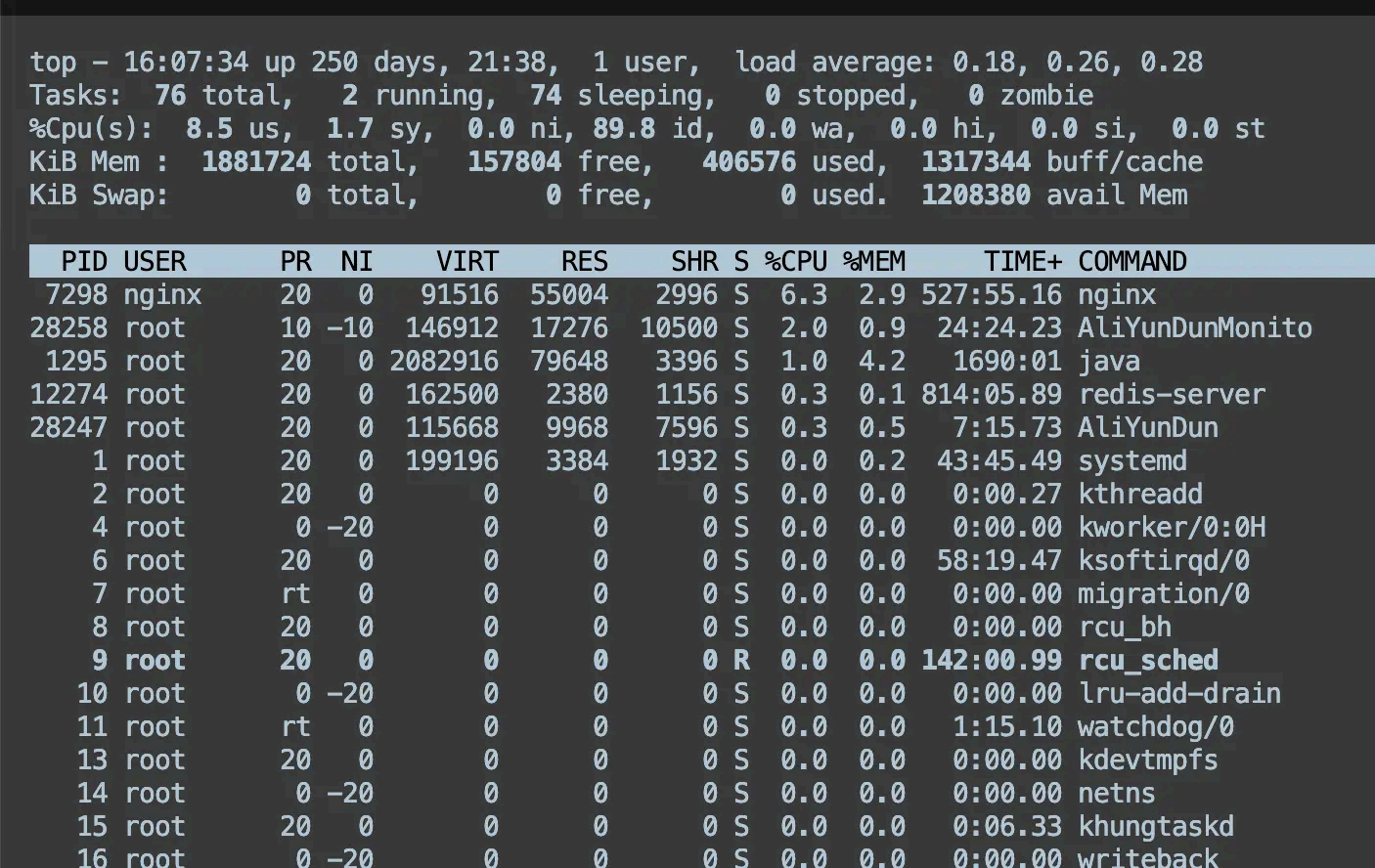
可以通过 ps 命令或者 top 命令来查 看进程的状态。
比如我想看 nginx 进程的状态,可以在 linux 输入这条命令:

top 命令除了能看进程的状态,还能看到系统的信息,比如系统负载、内存、cpu 使用率等等
linux 如何查看线程状态?
在 ps 和 top 命令加一下参数,就能看到线程状态了:
top -H
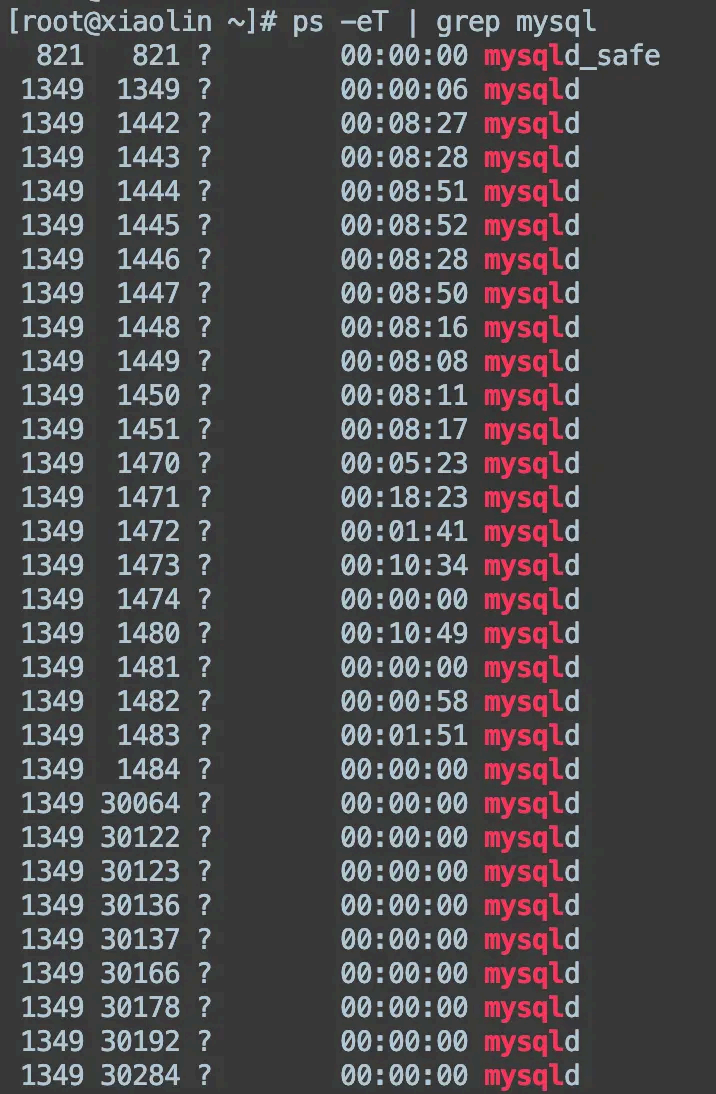
ps -eT | grep <进程名或线程名 >网络
如何查看网络连接情况?
可以通过 netstat 命令来查 看网络连接的情况,比如下面,我通过 命令:
netstat -napt
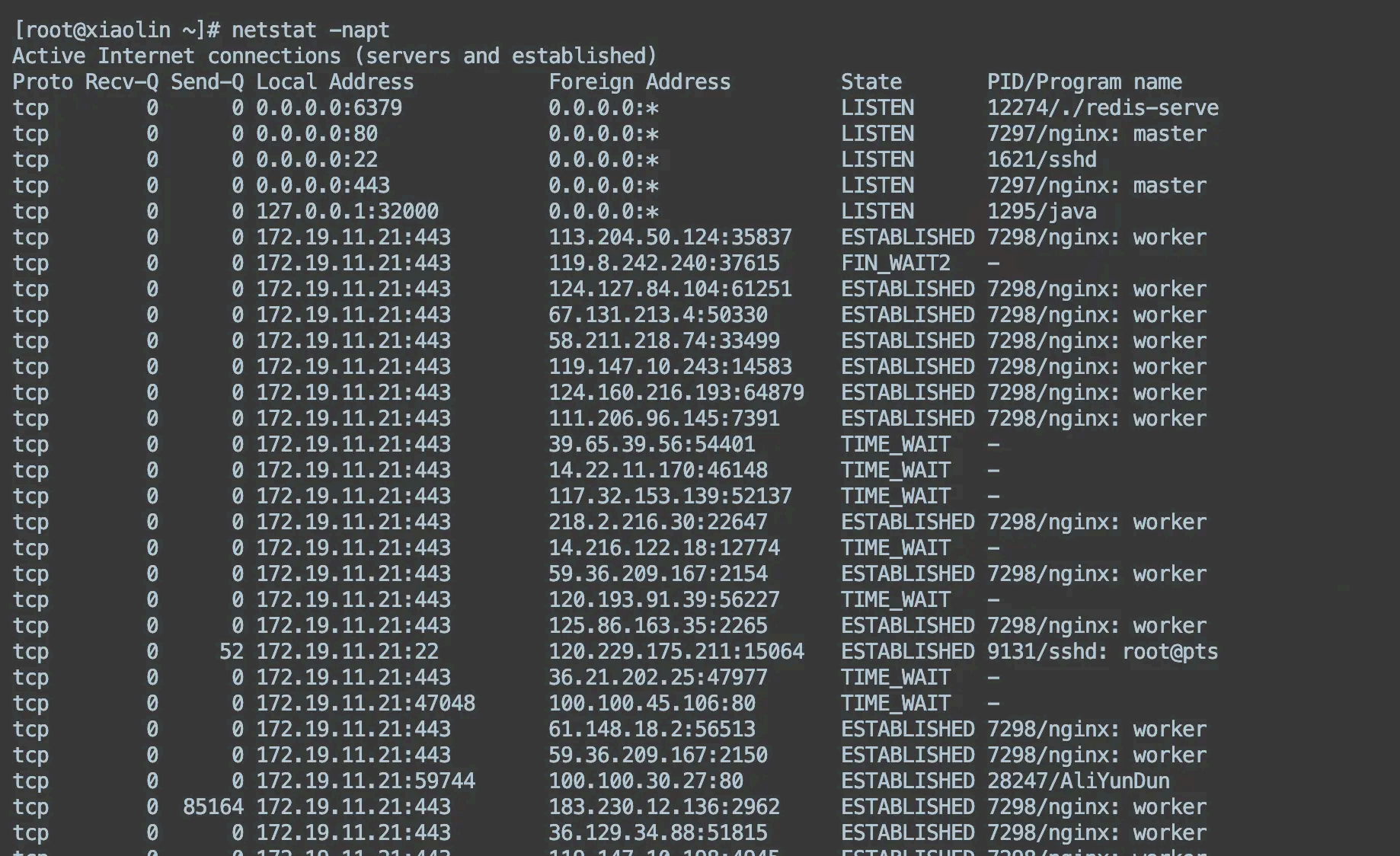
显示了服务器上的 tcp 连接状态,可以观察到每一个 tcp 连接的状态,以及四元组信息(源 ip 地址、目标 ip 地址 ,源端口、源 ip )
tcp 连接过程?
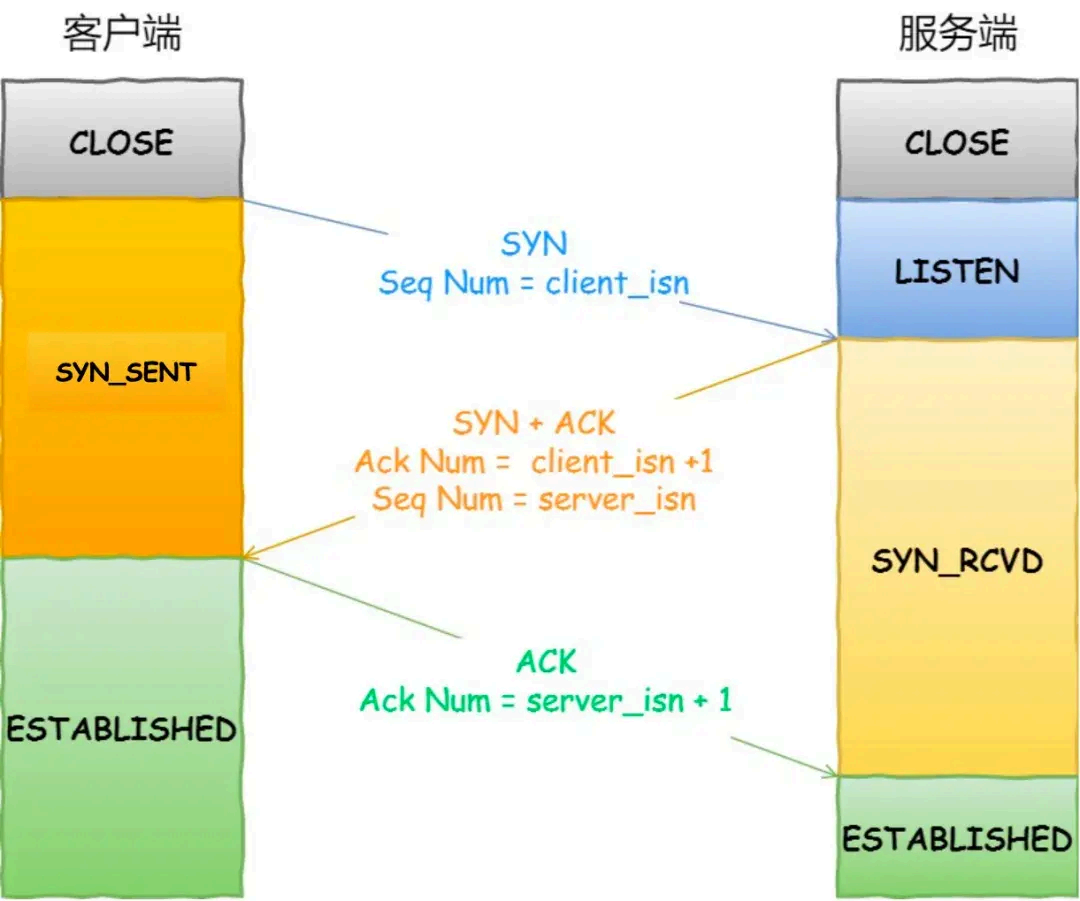
一开始,客户端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端口,处于 LISTEN 状态
客户端会随机初始化序号(client_isn ),将此序号置于 TCP 首部的「序号」字段中,同时把SYN 标志位置为 1,表示 SYN 报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。
服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn ),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1。最后把该报文发给客户端,该报文也不 包含应用层数据,之后服务端处于 SYN-RCVD 状态。
客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报 文发送给服务端,这次报文可以携带客户到服务端的数据,之后客户端处于 ESTABLISHED 状态。
服务端收到客户端的应答报文后,也进入 ESTABLISHED 状态。
server a 和server b ,如何判断两个 服务器正常连接?出错怎么办?
直不会发送数据给客户端,那么服务端是永远无法感知到客户端宕机这个事 件的,也就是服务端的 TCP 连接将一直处于 ESTABLISH 状态,占用着系统资源。
为了 避免这种情况,TCP 搞了个 保活机制。这个机制的原理是这样的:定义一个时间段,在这个时间段内,如果没有任何 连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔 ,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
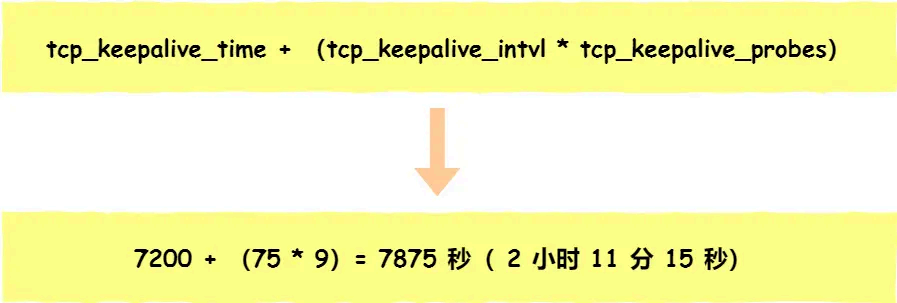
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔 ,以下都为默认值:
net.ipv4.tcp_keepalive_time =7200
net.ipv4.tcp_keepalive_intvl =75
net.ipv4.tcp_keepalive_probes =9
tcp_keepalive_time=7200 :表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何 连接相关的活动,则会启动保活机制
tcp_keepalive_intvl=75 :表示每次 检测间隔 75 秒;
tcp_keepalive_probes=9 :表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。也就是说在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。
注意,应用程序若想使用 TCP 保活机制需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。
如果开启了 TCP 保活,需要考虑以下几种情况:
第一种,对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
第二种,对端主机宕机并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快 就会发现 TCP 连接已经被重置。
第三种,是对端主机宕机(注意不是进程崩溃,进程崩溃后操作系统在回收进程资源的时候,会发送 FIN 报文,而主机宕机则是无法感知的,所以需要 TCP 保活机制来探测对方是不是发生了主 机宕机),或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
TCP 保活的这个机制检测的时间是有点长,我们可以自己在应用层实现一个心跳机制。
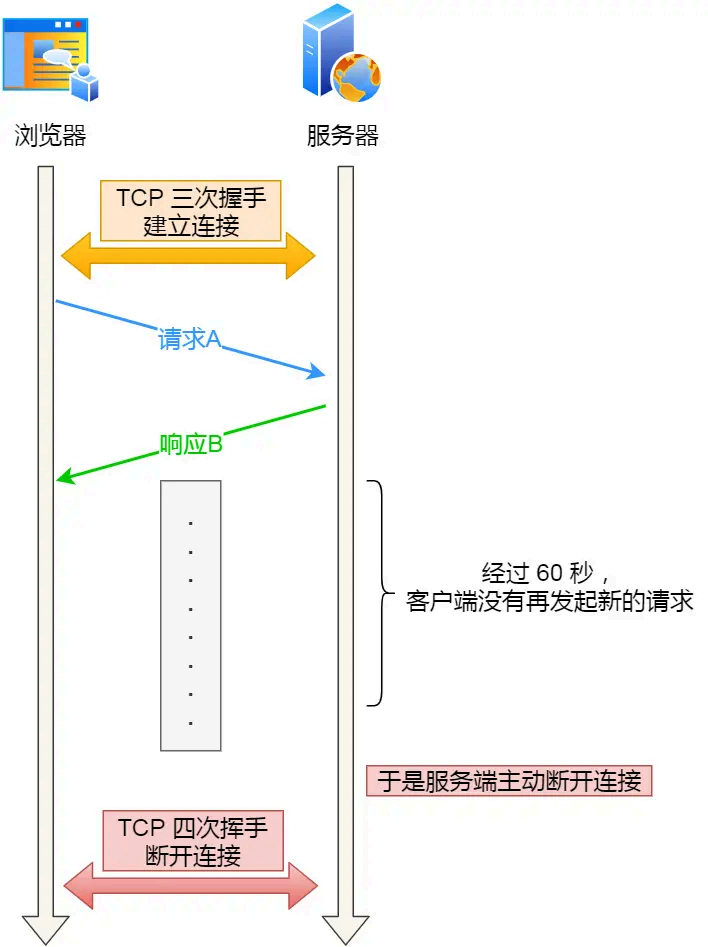
比如,web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时 间。如果设置了 HTTP 长连接的超时时 间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在完成一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。
项目
因为项目写了 raft 分布式 kv 的项目,问了一下 raft 算法相关的问题
一致性是怎么保证的
leader 选举过程是怎么样的?
leader 崩溃后重新加入如何保 证日志一致
手撕
给了一道go 相关题目,看打印出什么 ,关于append 的
hard 算法:抽五星卡概率,给了个 思路,没写出来,目测gg 了