
淘宝 Java 面试
淘宝 Java 面试
阿里巴巴 的淘天集团校招薪资也开了,也就是做淘宝业务的集团,上来跟大家汇报汇报。
25 届淘天集团的后端开发的校招薪资情况:
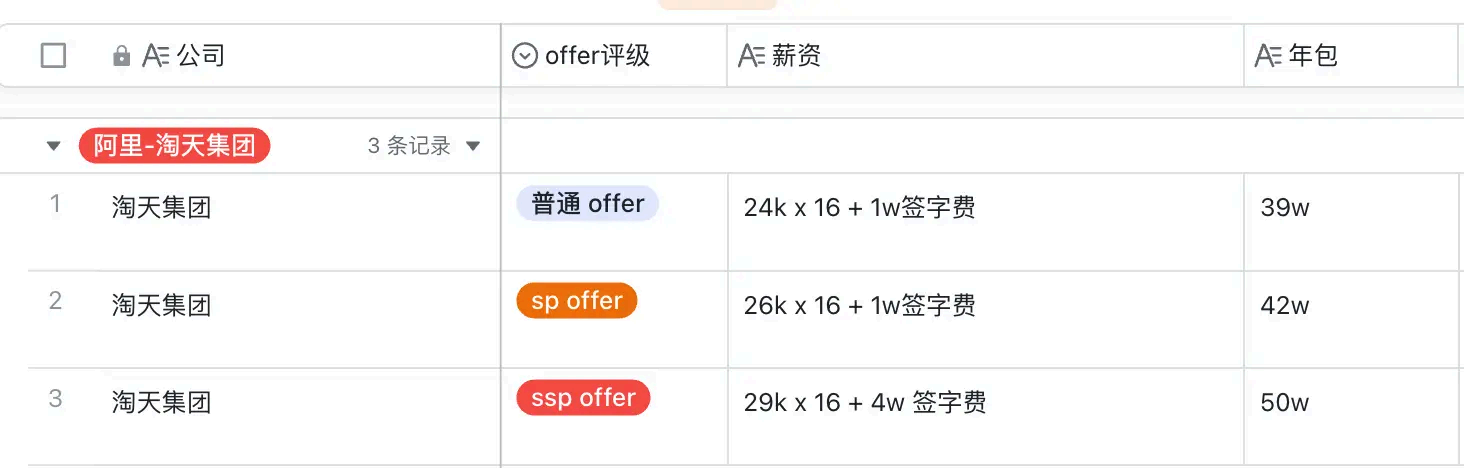
ssp offer :29k x 16 + 4w 签字费,同学 bg 硕士 211 ,base 杭州
sp offer :26k x 16 + 1w 签字费,同学 bg 未知,base 杭州
普通 offer :24k x 16 + 1w 签字费,同学 bg 硕士985 ,base 杭州
除此之外,还有一些补贴福利,房补 2k/ 月(共两年),交通费 800 元/月,搬家费 6k (一次性),杭州市人才补贴等等 。
整体上,跟蚂蚁 集团 25 届薪资 差不多,大概率阿里巴巴 其他集团的校招开奖薪资也是类似。
今天给大家分享阿里巴巴 Java 校招面经,同学的面试感受是「吹爆阿里,整个面试过程体验很不错,面试官一直引导」。
可惜同学没把握住,后面还是挂了。
考察内容还是比较多,我帮大家罗列了一下:
数据库:SQL 与 NOSQL ,数据库场景
Redis :持久化
MySQL :存储引擎、事务、锁
操作系统:进程线程、linux 命令
Java :线程、线程池、容器、面向对象特性
网络:网络通信协议

数据库
数据库怎么分类,描述一下你对这些数据库的理解?
按照数据模型来分类的话,主要分为关系型数据库和非关系型数据库
关系型数据库:基于关系模型组织 数据的数据库,如MySQL 、Oracle 等。
非关系型数据库:不使用传统表格形式 存储数据的数据库,如MongoDB 、Redis 等。
我的理解是,数据库是用于存储、管理和检索数据的系统,关系型数据库使用结构化查询语言(SQL )来管理数据,适用于需要保证数据一致性和完整性的场景;NoSQL 数据库则更加灵活,适用于需要处理大量非结构化数据或需要高可伸缩性的场景。
什么 情况使用MySQL ,什么 情况使用Redis ?
当需要存储结构化数据,并且需要支持复杂的查询操作时,和需要支持事务处理时,可以选择MySQL 。
当需要快速访问和处理数据的缓存时,可以选择Redis ,能够提供快速的数据读取和写入。
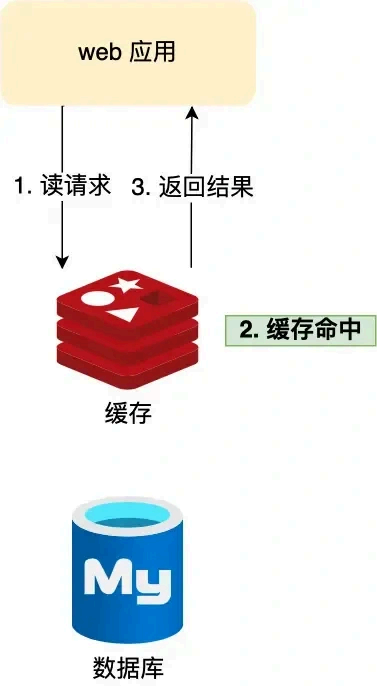
一般Redis 会作 为MySQL 的缓存,提高服务器系统的查询性能。假如用户第一次访问 MySQL 中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据缓存在 Redis 中,这 样下一次再访问这些数据的时候就可以直接从缓存中获取了,操作 Redis 缓存就是直接操作内存,所以速度相当快 。
Redis
Redis 有什么 持久化策略?
Redis 的读写操作都是在内存中,所以 Redis 性能才会高,但是当 Redis 重启后 ,内存中的数据就会丢失,那为了 保证内存中的数据不会丢失,Redis 实现了数据持 久化的机制,这个机制会把数据存储到磁盘,这样在 Redis 重启就能够从磁盘中恢复原有的数据。
Redis 共有三种数据持 久化的方式:
AOF 日志:每执行一条写操作命令,就把该命令以 追加的方式写入到一个文件里;
RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RDB 的优点;
MySQL
MySQL 有哪2种引擎,说一下它们的区别?
MySQL 中常用的存储引擎分别 是:MyISAM 存储引擎、innoDB 存储引擎,他们的区别在于:事务:InnoDB 支持事务,MyISAM 不支持事务,这是 MySQL 将默认存储引擎从 MyISAM 变成InnoDB 的重要原因之一。
索引结构:InnoDB 是聚簇索引,MyISAM 是非聚簇索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主 键太大,其他索引也都会很大。而 MyISAM 是非聚簇索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
锁粒度:InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。
count 的效率:InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快 。
MySQL 两个 线程的update 语句同时处理一条数据,会不会有阻塞?
如果是两个事 务同时更新了 id = 1 ,比如 update ... where id = 1 ,那么是会阻塞的。因为 InnoDB 存储引擎实现了行级锁。
当A事务对 id =1 这行记录进行更新时,会对主键 id 为 1 的记录加X类型的记录锁,这样第二事务对 id = 1 进行更新时,发现已经有记录锁了,就会陷入阻塞状态。
滥用事务,或者一个事 务里有特别多sql 的弊端?
事务的资源在事务提交之 后才会释放的,比如存储资源、锁。
如果一个事 务特别多 sql ,那么会带来这些问题:
如果一个事 务特别多 sql ,锁定的数据太多 ,容易造成大量的死锁和锁超时。
回滚记录会占用大量存储空间,事务回滚时间长。在MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前 一个状态的值,sql 越多,所需要保存的回滚数据就越多。
执行时间长,容易造成主从 延迟,主库上必须等事务执行完成才 会写入binlog ,再传给备库。所以,如果一个主 库上的语句执行10 分钟,那这个事 务很可能就会导致从库延迟10 分钟
两条update 语句处理一张表的不同的主键范围的记录,一个<10 ,一个>15 ,会不会遇到阻塞?底层是为什么 的?
不会,因为锁住的范围不一样,不会形成冲突。
第一条 update sql 的话( id<10 ),锁住的范围是(-♾,10 )
第二条 update sql 的话(id >15 ),锁住的范围是(15 ,+♾)如果2个范围不是主键或索引?还会阻塞吗?
如果2范围查询的字段不是索引的话,那就代表 update 没有用到索引,这时候触发了全表扫描,
全部索引都会加行级锁,这时候第二条 update 执行的时候,就会阻塞了。
因为如果 update 没有用到索引,在扫描过程中会对索引加锁,所以全表扫描的场景下,所有记录都会被加锁,也就是这条 update 语句产生了 4 个记录锁和 5 个间隙 锁,相当于锁住了全表。

除了表锁,行锁这些,还有别的形式 的锁吗?
还有全局锁。全局锁:通过flush tables with read lock 语句会将整个数据库就处于只读状态了,这时其他线程执行以下操作,增删改或者表结构修改都会阻塞。全局锁主要应用于做全库逻辑备份,这样在备份数据库期间,不会因为数据或表结构的更新,而出现备份文件的数据与预期的不一样。
操作系统
谈一下对线程和进程的理解
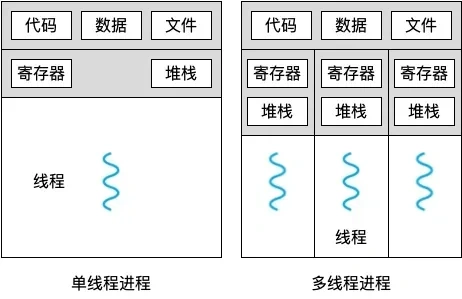
本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位在开销方面:每个进程都有独立的代码和数据空间(程序上下 文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器( PC ),线程之间切换的开销小稳定性方面:进程中某个线程如果崩溃了,可能会导致整个进程都崩溃。而进程中的子进程崩溃,并不会影响其他进程。
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU 外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
多线程比单线程的优势,劣势
多线程比单线程的优势:提高程序的运行效率,可以充分利 用多核处理器的资源,同时处理多个任务,加快程序的执行速度。
多线程比单线程的劣势 :存在多线程数据竞争访问的问题,需要通过锁机制来保证线程安全,增加了加锁的开销,并且还会有死锁的⻛险。多线程会消耗更多系统资源,如CPU 和内存,因为每个线程都需要占用一定的内存和处理时间。
Linux 操作系统中哪个命令可以查看端口被哪个应用占用?使用 lsof 命令:
可以使 用 lsof 命令或 netstat 命令查看端口被哪个应用占用。
使用 netstat 命令:
netstat -tulnp | grep 端口号
这两个 命令都可以帮助你找到哪个应用程序占用了特定的端口。
Java
Java 创建线程有几种方式
方式一:继承Thread 类并重写run() 方法。
public class CreatingThread01 extends Thread {
@Override
public void run() {
System.out.println(getName() + " is running");
}
public static void main(String[] args) {
new CreatingThread01().start();
new CreatingThread01().start();
new CreatingThread01().start();
new CreatingThread01().start();
}
}采用继承Thread 类方式
优点: 编写简单,如果需要访问当前线程,无需使用Thread.currentThread () 方法,直接使用this ,即可获得当 前线程
缺点:因为线程类已经继 承了Thread 类,所以不能再继承其他的父类
方式二:实现Runnable 接口并实现run() 方法,然后将实现了Runnable 接口的类传递给Thread 类。
public class CreatingThread02 implements Runnable {
@Override
public void run() {
}
public static void main(String[] args) {
new Thread(new CreatingThread02()).start();
new Thread(new CreatingThread02()).start();
new Thread(new CreatingThread02()).start();
new Thread(new CreatingThread02()).start();
}
}采用实现Runnable 接口方式:
优点:线程类只是实现了Runable 接口,还可以继承其他的类。在这种方式下,可以多个线程共享同一个目标对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU 代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
缺点:编程稍 微复杂,如果需要访问当前线程,必须使用Thread.currentThread() 方法。
方式三:使用Callable 和Future 接口通过Executor 框架创建线程。
public class CreatingThread03 implements Callable<Long> {
@Override
public Long call() throws Exception {
Thread.sleep(2000);
System.out.println(Thread.currentThread().getId() + " is running");
return Thread.currentThread().getId();
}
public static void main(String[] args) throws ExecutionException, InterruptedException{
FutureTask<Long> task = new FutureTask<>(new CreatingThread03());
new Thread(task).start();
System.out.println("等待完成任务");
Long result = task.get();
System.out.println("任务结果:" + result);
}
}采用实现Callable 接口方式:
缺点:编程稍 微复杂,如果需要访问当前线程,必须调用Thread.currentThread() 方法。
优点:线程只是实现Runnable 或实现Callable 接口,还可以继承其他类。这种方式下,多个线程可以共享一个target 对象,非常适合多线程处理同一份资源的情形。
线程池有哪些优势?
减少线程创建和销毁的开销:频繁地创建和销毁线程会消耗大量系统资源,线程池通过重用已存在的线程来减少这种开销。
提高响应速度:当任务到 达时,无需等待线程的创建即可立即执行,因为线程池中已经有等待的线程。
说一下面向对象3大特性理解?
Java 面向对象的三大特性包括:封装、继承、多态:
封装:封装是指将对 象的属性(数据)和行为(方法)结合在一起,对外隐藏对象的内部细节,仅通过对象提供的接口与外界交互 。封装的目的是增强安全性和简化编程,使得对象更加独立。
继承:继承是一种可以使 得子类自动共享父类数据结构和方法的机制。它是代码复用的重要手段,通过继承可以建立类与类之间的层次关系,使得结构更 加清晰。
多态:多态是指允许不同类的对象对同一消息作出响应。即同一个接口,使用不同的实例而执行不同操作。多态性 可以分为编译时多态(重载)和运行时多态(重写)。它使得程序具有良好的灵活性和扩展性。
Java 有什么 常用的集合类?
Java 中常用的集合类主要分为四个类别:List 、Set 、Map 、Queue 。
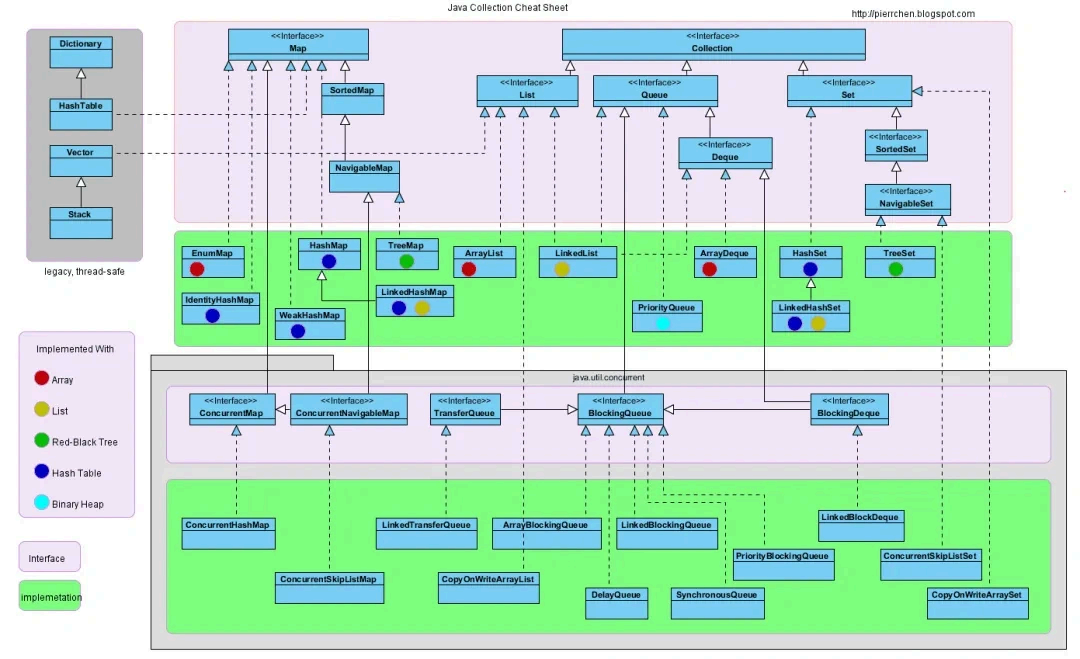
List (列表):是一个有序的集合,可以包含重复的元素。主要实现类有 ArrayList 、LinkedList 和 Vector 。 ArrayList 是基于动态数组实现,适合随机访问元素; LinkedList 基于双向链表实现,适合插入、删除操作频繁的场景。
Set (集合):是一个不 允许有重复元素的集合。主要实现类有 HashSet 、 LinkedHashSet 和TreeSet 。 HashSet 基于哈希表实现,最常用; LinkedHashSet 继承自 HashSet ,但是可以维护元素插入的顺序; TreeSet 基于红黑树实现,元素会按照某种比较规则进行排序。
Map (映射):是一种键值对的集合,提供键到值的映射。主要实现类有 HashMap 、LinkedHashMap 和 TreeMap 。 HashMap 是基于哈希表实现,存取高效; LinkedHashMap 基于HashMap 实现,但可以保 持插 入顺序; TreeMap 基于红黑树实现,按照键的自然顺序或者构造时提供的 Comparator 进行排序。
Queue (队列):是一种先进先出(FIFO )的数据结构。常用实现类有 LinkedList (也实现了Deque 接口), PriorityQueue 等。 PriorityQueue 是基于优先级堆实现的无界优先级队列,元素按照自然顺序或者构造时提供的 Comparator 决定的顺序被访问。
有哪些集合类是线程安全的,哪些是不安全的?
Vector 、HashTable 、Properties 是线程安全的;
ArrayList 、LinkedList 、HashSet 、TreeSet 、HashMap 、TreeMap 等都是线程不安全的。
数组和链表有什么 区别?
访问效率:数组可以通过索引直接访问任何位 置的元素,访问效率高,时间复杂度为O(1) ,而链表需要从头节点开始遍历到目标位置,访问效率较低,时间复杂度为O(n) 。
插入和删除操作效率:数组插入和删除操作可能需要移动其他元素,时间复杂度为O(n) ,而链表只需要修改指针指向,时间复杂度为O(1) 。
缓存命中率: 由于数组元素在内存中连续存储,可以提高CPU 缓存的命中率,而链表节点不连续存储,可能导致CPU 缓存的命中率较低,频繁的缓存失效会影响性能。
应用场景:数组适合静态大小、频繁访问元素的场景,而链表适合动态大小、频繁插入、删除操作的场景
堆和栈的区别?
分配方式:堆是动态分配内存,由程序员手动申请和释放内存,通常用于存储动态数据结构和对象。栈是静态分配内存,由编译器自动分 配和释放内存,用于存储函数的局部变量和函数调用信息。
内存管理:堆需要程序员手动管理内存的分配和释放,如果管理不当可能会导致内存泄漏或内存溢出。栈由编译器自动管理内存,遵循后进先出的原则,变量的生命周 期由其作用域决定,函数调用时分配内存,函数返回时释放内存。
大小和速度:堆通常比栈大,内存空间较大,动态分配和释放内存需要时间开销。栈大小有限,通常比较小,内存分配和释放速度较快,因为是编译器自动管理。
Set 集合有什么 特点?如何实现key 无重复的?
set 集合特点:Set 集合中的元素是唯一的,不会出现重复的元素。
set 实现原理:Set 集合通过内部的数据结构(如哈希表、红黑树等)来实现key 的无重复。当向Set 集合中插入元素时,会先根据元素的hashCode 值来确定元素的存储位置,然后再通过equals 方法来判断是否已经存在相同的元素,如果存在则不会再次插入,保证了元素的唯一性。
有序的Set 是什么 ?记录插入顺序的集合是什么 ?
有序的 Set 是TreeSet 和LinkedHashSet 。TreeSet 是基于红黑树实现,保证元素的自然顺序。
LinkedHashSet 是基于双重链表和哈 希表的结合来实现元素的有序存储,保证元素添加的自然顺序记录插入顺序的集合通常指的是LinkedHashSet ,它不仅 保证元素的唯一性,还可以保 持元素的插入顺序。当需要在Set 集合中记录元素的插入顺序时,可以选择使用LinkedHashSet 来实现。
网络
网络有什么 常用的通信协议?
HTTP :用于在Web 浏览器和Web 服务器之间传输超文本的协议,是目前最常见的应用层协议。
HTTPS :在HTTP 的基础上添加了SSL/TLS 加密层,用于在不安全的网络上安全地传输数据。
TCP :面向连接的传输层协议,提供可靠的数据传输服务,保证数据的顺序和完整性。
UDP :无连接的传输层协议,提供了数据包传输的简单服务,适用于实时性要求高的应用。
IP :网络层协议,用于在网络中传输数据包,定义了 数据包的格式和传输规则。
前后端交互 用的是什么 协议?
用HTTP 和HTTPS 协议比较多。
前端通过HTTP 协议向服务器端发送请求,服务器端接收请求并返回相应的数据,实现了前后端的交互 。HTTP 协议简单、灵活,适用于各种类型的应用场景。
算法
算法:快乐数,每一位平方求和,循环操作是否可 以变为1