
滴滴 ⼆⾯
滴滴 Java ⾯试
25 届滴滴 开发岗位的校招薪资如下,普通 offer 31.5w 年薪,sp offer 37.5w 〜40.5w 年薪,ssp offer 45w 年薪。

滴滴 的普通 offer 相⽐其他⼤⼚确实⽐较⼀般了,能进滴滴 的同学,⼿上也 会有其他⼤⼚的
offer ,这种情况下⼤概率会把滴滴 给拒掉了。
不过,也有同学跟我反馈,他原本滴滴 开的是 21k ,但是⾃⼰后⾯拿到了其他 offer ,后⾯滴滴 给
他加到 了 25k ,offer 档次提升到了 sp offer ,所以多积攒 offer ,对谈薪是有⾮常⼤的好处 的。
滴滴 是 11 ⽉底开奖,训练营也有同学拿到了滴滴 sp offer ,滴滴 hr 当时跟他聊了很久,还是⾮常有诚意的。
那话说回来,滴滴 ⾯试难度如何呢?
这次来分享⼀位同学滴滴 Java 后端开发的校招⾯经,涵盖⼀⼆⾯,主要考察的知识点是⽹络协
议、Redis 、MySQL 、操作系统、算法这些内容, 编程语⾔⽅⾯的基本没有问,⼤概率滴滴 这个部⻔⽤ Go 技术栈的,⾯试官对 Go 熟悉⼀些,Java ⽅⾯就问的⽐较少。

开场三连问
⾃我介绍
实习经历介绍
项⽬介绍
TCP 和UDP 区别是什么 ?
连接:TCP 是⾯向连接的传输层协议,传输数据前先要建⽴连接;UDP 是不需要连接,即刻传
输数据。
服务对象:TCP 是⼀对⼀的两点服务,即⼀条连接只有两个 端点。UDP ⽀持⼀对⼀、⼀对多、
多对多的交互 通信
可靠性:TCP 是可靠交付 数据的,数据可以⽆差错、不丢 失、不重复、按序到达。UDP 是尽最
⼤努⼒交付 ,不保证可靠交付 数据。但是我们可以基于 UDP 传输协议实现⼀个可靠的传输协
议,⽐如 QUIC 协议
拥塞控制、流量控制:TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。UDP 则没
有,即使⽹络⾮常拥堵了,也不 会影响 UDP 的发送速 率。
⾸部开销:TCP ⾸部⻓度较⻓,会有⼀定的开销,⾸部在没有使⽤「选项」字段时是 20 个字
节,如果使⽤了「选项」字段则会变⻓的。UDP ⾸部只有 8 个字节,并且是固定不变的,开销
较⼩。
传输⽅式:TCP 是流式传输,没有边界,但保 证顺序和可 靠。UDP 是⼀个包⼀个包的发送,是
有边界的,但可能会丢包和乱序。
UDP 怎么保证可靠性?
UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议 可以实现类似 TCP 的可靠性传输,在http3 就⽤
了 quic 协议。
连接迁移:QUIC ⽀持在⽹络变化 时快速迁移连接,例如从WiFi 切换到移动数据⽹络,以保 持连
接的可靠性。
重传机制:QUIC 使⽤重传机制来确保丢失的数据包能够被重新发送,从⽽提⾼数据传输的可靠
性。
前向纠错:QUIC 可以使 ⽤前向纠错技术,在接收端修复部分丢失的数据,降低重传的需求,提
⾼可靠性和传输效率。
拥塞控制:QUIC 内置了拥塞控制机制,可以根据⽹络状况动态调整数 据传输速率,以避免⽹络
拥塞和丢包,提⾼可靠性。
HTTP 原理是什么 ?
HTTP (超⽂本传输协议)是应⽤层协议,⽤于在 Web 浏览器和 Web 服务器之间传输超⽂本数
据。它基于请求 - 响应模型进⾏通信,就像客⼾端(通常是浏览器) 和服务器之间的对话。
HTTP 是基于 TCP 协议来实现的,发送 HTTP 请求的照顾去,需要先完成 TCP 三次握⼿。
⼀个完整的 HTTP 请求从请求⾏开始。请求⾏包含了请求⽅法、请求的 URL (统⼀资源定位符)
和 HTTP 协议版本。服务器收到请求后,会返回⼀个 HTTP 响应,响应的第⼀⾏是状态⾏。状
态⾏包含了 HTTP 协议版本、状态码和状态消息。
HTTP 是⼀种⽆状态协议,这意味着每个请求都是独⽴的,服务器不会记住之前的请求信息。例
如,当你在⼀个电商⽹站上浏览商品,每次 请求⼀个商品⻚⾯时,服务器不会⾃动知道你之前
浏览过哪些商品。为了 实现⼀些需要记住⽤⼾状态的功能,如购物⻋、登录状态等,通常会使
⽤ Cookie 、Session 等技术来 跟踪⽤⼾的状态。
HTTP 可以传 输多种类型的数据,包括⽂本、图像、⾳频、视频等,并且可以通过各种请求⽅法
和响 应头来满⾜不同的应⽤场景。例如,通过 Content - Type 响应头可以灵活地告知客⼾端数
据类型,通过 Accept 请求头可以让客⼾端表达⾃⼰对数据类型的需求。
TCP 协议⾥的TIME_WAIT 状态是什么 ?
TIME_WAIT 状态的存在是为了 确保⽹络连接的可靠关闭。只有主动发起关闭连接的⼀⽅(即主动
关闭⽅)才会有 TIME_WAIT 状态。
TIME_WAIT 状态的需求主要有两个 原因:
防⽌具有相同「四元组」的「旧」数据包被收到:在⽹络通信中,每个 TCP 连接都由源 IP 地址、源端⼝号、⽬标 IP 地址 和⽬标端⼝号这四个元素唯⼀标识,称为「四元组」。当⼀⽅主动
关闭连接后,进⼊ TIME_WAIT 状态,它仍然可以接收到⼀段时间内来⾃对⽅的延迟数据包。这
是因为⽹络中可能存在被延迟传输的数据包,如果没有 TIME_WAIT 状态的存在,这些延迟数据
包可能会被错误地传递给新的连接,导致数据混乱。通过保持 TIME_WAIT 状态,可以防⽌旧的
数据包⼲扰新的连接。
保证「被动关闭连接」的⼀⽅能被正确关闭:当连接的被动关闭⽅接收到主动关闭⽅的 FIN 报
⽂(表⽰关闭连接),它需要发送⼀个确认 ACK 报⽂给主动关闭⽅,以完成连接的关闭。然
⽽,⽹络是不可靠的,ACK 报⽂可能会在传输过 程中丢 失。如果主动关闭⽅在收到 ACK 报⽂之
前就关闭连接,被动关闭⽅将⽆法正常完成连接的关闭。TIME_WAIT 状态的存在确保了被动关
闭⽅能够接收到最后的 ACK 报⽂,从⽽帮助其正常关闭连接。
aio 、nio 、bio 区别是什么 ?
BIO (blocking IO ):就是传统的 java.io 包,它是基于流模型实现的,交互 的⽅式是同步、阻塞
⽅式,也就是说在读⼊输⼊流或者输出流时,在读写动作完成之前,线程会⼀直阻塞在那⾥,
它们之间的调⽤是可靠的线性顺序。优点是代码⽐较简单、直观;缺点是 IO 的效率和扩展性很
低,容易成为应⽤性能瓶颈。
NIO (non-blocking IO ) :Java 1.4 引⼊的 java.nio 包,提供了 Channel 、Selector 、Buffer 等
新的抽象,可以构建多路复⽤的、同步⾮阻塞 IO 程序,同时提供了更接近操作系统底层⾼性能
的数据操作⽅式。
AIO (Asynchronous IO ) :是 Java 1.7 之后引⼊的包,是 NIO 的升级版本,提供了异步⾮堵
塞的 IO 操作⽅式,所以⼈们叫它 AIO (Asynchronous IO ),异步 IO 是基于事 件和回调机制实
现的,也就是应⽤操作之后会直接返回,不会堵塞在那⾥,当后台 处理完成,操作系统会通知相应的线程进⾏后续的操作。
redis 数据结构你知道哪些?你⽤到了哪种?
Redis 提供了丰 富的数据类型,常⻅的有五种数据类型:String (字符串),Hash (哈希),List
(列表),Set (集合)、Zset (有序集合)。


随着 Redis 版本的更新,后⾯⼜⽀持了四种数据类型:BitMap (2.2 版新增)、HyperLogLog (2.8 版新增)、GEO (3.2 版新增)、Stream (5.0 版新增)。Redis 五种数据类型的应⽤场景:
String 类型的应⽤场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
List 类型的应⽤场景:消息队列(但是有两个 问题:1. ⽣产者需要⾃⾏实现全局唯⼀ ID ;2. 不
能以消费组形式 消费数据)等。
Hash 类型:缓存对象、购物⻋等。
Set 类型:聚合计算(并集、交集、差集)场景,⽐如点赞、共同关注、抽奖活动等。
Zset 类型:排序场景,⽐如排⾏榜、电话和姓名排序等。
Redis 后续版本⼜⽀持四种数据类型,它们的应⽤场景如下:
BitMap (2.2 版新增):⼆值状态统计的场景,⽐如签到、判断⽤⼾登陆状态、连续签到⽤⼾总
数等;
HyperLogLog (2.8 版新增):海量数据基数统计的场景,⽐如百万级⽹⻚ UV 计数等;
GEO (3.2 版新增):存储地理位置信息的场景,⽐如滴滴 叫⻋;
Stream (5.0 版新增):消息队列,相⽐于基于 List 类型实现的消息队列,有这两个 特有的特
性:⾃动⽣成全局唯⼀消息ID ,⽀持以消费组形式 消费数据。
redis 主节点挂了怎么办?
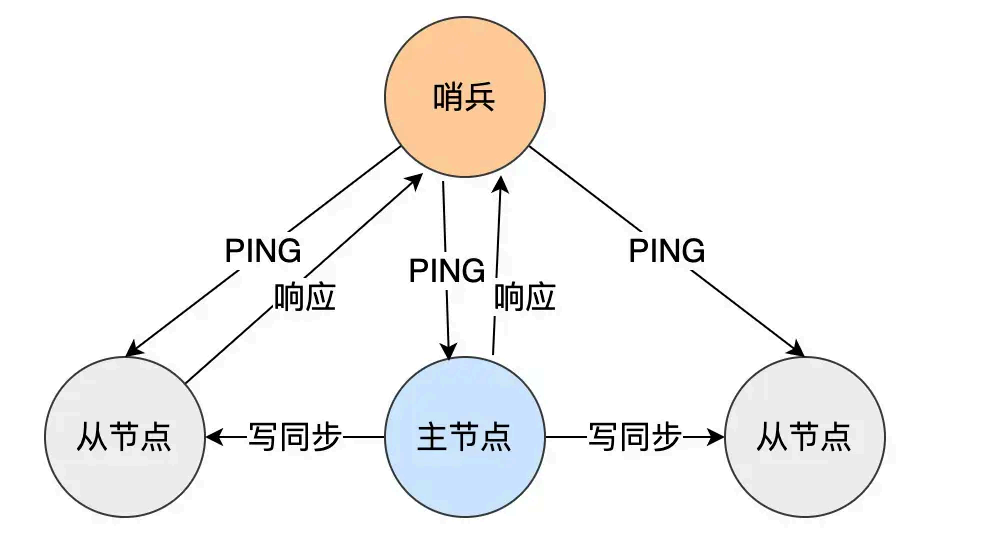
可以增加哨兵机制,哨兵当发现主节点挂了,会进⾏主从 ⾃动切 换,它会监测主节点是否存活,
如果发现主节点挂了,它就会选举⼀个从 节点切换为主 节点,并且把新主节点的相关信息通知给
从节点和客⼾端。
Redis Sentinel (哨兵)会定期向主节点和从节点发送 ping 命令来检查它们的状态。例如,每 1 秒
(可配置)发送⼀次 ping ,如果主节点在规定时间(如 down - after - milliseconds 配置项指定的
时间,默认 30 秒)内没有响应,Sentinel 就会认为主 节点挂了。
当 Sentinel 判定主节点挂了后,会在从节点中选举⼀个新的主节点。选举的依据主要是从节点的
优先级(可以在 Redis 配置⽂件中设置,默认是 100 ,数字越⼤优先级越⾼)、数据复制的偏移量
(与旧主节点数据同步程度,偏移量越⼤说明数据越新)和运⾏ ID (⽤于区分不同的节点)。
新主节点选举出来后,其他从 节点会向新主节点进⾏数据同步。Redis 从节点通过复制偏移量
(replica - offset )来确定从哪⾥开始复 制数据。新主节点会将⾃⼰的数据发送给从节点,从节点
接收并更新⾃⼰的数据,以达到数据的⼀致性。
线程、进程、协程区别是什么 ?
⾸先,我们来谈谈 进程。进程是操作系统中进⾏资源分配和调度的基本单位,它拥有⾃⼰的独
⽴内存空间和系统资源。每个进程都有独⽴的堆和栈,不与 其他进程共享。进程间通信需要通
过特定的机制,如管道、消息队列、信号量等。由于进程拥有独⽴的内存空间,因此其稳定性
和安全性相对较⾼,但同时上下 ⽂切换的开销也较⼤,因为需要保存和恢复整个进程的状态。
接下来是线程。线程是进程内的⼀个执⾏单元,也是CPU 调度和分派的基本单位。与进程不
同,线程共享进程的内存空间,包括堆和全局变量。线程之间通信更加⾼效,因为它们可以直
接读写共 享内存。线程的上下 ⽂切换开销较⼩,因为只需要保存和恢复线程的上下 ⽂,⽽不是
整个进程的状态。然⽽,由于多个线程共享内存空间,因此存在数据竞争和线程安全的问题,
需要通过同步和互斥机制来解决。
最后是协程。协程是⼀种⽤⼾态的轻量级线 程,其调度完全由⽤⼾程序控制,⽽不需要内核的
参与。协程拥有⾃⼰的寄存 器上下 ⽂和栈,但与其他协程共享堆内存。协程的切换开销⾮常
⼩,因为只需要保存和恢复协程的上下 ⽂,⽽⽆需进⾏内核级的上下 ⽂切换。这使得协程在处
理⼤量并发任务时具有⾮常⾼的效率。然⽽,协程需要程序员显式地进⾏调度和管理,相对于
线程和进程来说,其编程模型更为复杂。
⼿撕代码
⼿撕代码,题⽬忘了,⼒扣原题
滴滴 ⼆⾯
开场⼆连问
⾃我介绍
实习中 哪⾥体现了团队协作?
redis 分布式锁怎么实现?
分布式锁是⽤于分布式环境下并发控制的⼀种机制,⽤于控制某个资源在同⼀时刻只能被⼀个应
⽤所使⽤。如下图所⽰:

Redis 本⾝可以被多个客⼾端共享访问,正好就是⼀个共享存储系统,可以⽤来保存分布式锁,⽽
且 Redis 的读写性能⾼,可以应对⾼并发的锁操作场景。Redis 的 SET 命令有个 NX 参数可以实现
「key 不存在才插⼊」,所以可以⽤它来实现分布式锁:
如果 key 不存在,则显⽰插⼊成功,可以⽤来表⽰加锁成功;
如果 key 存在,则会显⽰插⼊失败,可以⽤来表⽰加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满⾜三个 条件。
加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个 操作,但需要以原⼦操作的⽅式完
成,所以,我们使 ⽤ SET 命令带上 NX 选项来实现加锁;
锁变量需要设置过期时间,以免客⼾端拿到锁后发⽣异常,导致锁⼀直⽆法释放,所以,我们
在 SET 命令执⾏时加上 EX/PX 选项,设置其过期时间;
锁变量的值需要能区分来⾃不同客⼾端的加锁操作,以免在释放锁时,出现误释放操作,所
以,我们使 ⽤ SET 命令设置锁变量值时,每个客⼾端设置的值是⼀个唯⼀值,⽤于标识客⼾
端;
满⾜这三个 条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
lock_key 就是 key 键;unique_value 是客⼾端⽣成的唯⼀的标识,区分来⾃不同客⼾端的锁操作;
NX 代表只在 lock_key 不存在时,才对 lock_key 进⾏设置操作;
PX 10000 表⽰设置 lock_key 的过期时间为 10s ,这是为了 避免客⼾端发⽣异常⽽⽆法释放锁。
⽽解锁的过程就是将 lock_key 键删除(del lock_key ),但不能乱删,要保证执⾏操作的客⼾端就
是加锁的客⼾端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客⼾端,是的
话,才将 lock_key 键删除。可以看到,解锁是有两个 操作,这时就需要 Lua 脚本来 保证解锁的原⼦性,因为 Redis 在执⾏ Lua 脚本时,可以以 原⼦性的⽅式执⾏,保证了锁释放操作的原⼦性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0end
这样⼀来,就通过使⽤ SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
redis 的hashset 底层数据结构是什么 ?
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
如果哈希类型元素个数⼩于 512 个(默认值,可由 hash-max-ziplist-entries 配置),所有
值⼩于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使 ⽤压缩列
表作为 Hash 类型的底层数据结构;
如果哈希类型元素不满⾜上⾯条件,Redis 会使 ⽤哈希表作为 Hash 类型的 底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来 实现了。
redis 持久化原 理是什么 ?
Redis 的读写操作都是在内存中,所以 Redis 性能才会⾼,但是当 Redis 重启后 ,内存中的数据就
会丢失,那为了 保证内存中的数据不会丢失,Redis 实现了数据持 久化的机制,这个机制会把数据
存储到磁盘,这样在 Redis 重启就能够从磁盘中恢复原有的数据。Redis 共有三种数据持 久化的⽅
式:
AOF ⽇志:每执⾏⼀条写操作命令,就把该命令以 追加的⽅式写⼊到⼀个⽂件⾥;
RDB 快照:将某⼀时刻的内存数据,以⼆进制的⽅式写⼊磁盘;
AOF ⽇志是如何实现的?
Redis 在执⾏完⼀条写操作命令后,就会把该命令以 追加的⽅式写⼊到⼀个⽂件⾥,然后 Redis 重
启时,会读取该⽂件记录的命令,然后逐⼀执⾏命令的⽅式来进⾏数据恢复。

我这⾥以「set name xiaolin 」命令作 为例⼦,Redis 执⾏了这条命令后,记录在 AOF ⽇志⾥的内
容如下图:

Redis 提供了 3 种写回硬盘的 策略, 在 Redis.conf 配置⽂件中的 appendfsync 配置项可以有以下
3 种参数可填:
Always ,这个单词的意思是「总是」,所以它的意思是每次 写操作命令执⾏完后,同步将 AOF
⽇志数据写回硬盘;
Everysec ,这个单词的意思是「每秒」,所以它的意思是每次 写操作命令执⾏完后,先将命令写
⼊到 AOF ⽂件的内核缓冲区,然后每隔⼀秒将缓冲区⾥的内容写回到硬盘;
No ,意味着不由 Redis 控制写回硬盘的 时机,转交给操作系统控制写回的时机,也就是每次 写
操作命令执⾏完后,先将命令写⼊到 AOF ⽂件的内核缓冲区,再由操作系统决定何时将缓冲区
内容写回硬盘。
我也把这 3 个写回策略的优缺点总结成了⼀张表格:

RDB 快照是如何实现的呢?
因为 AOF ⽇志记录的是操作命令,不是实际的数据,所以⽤ AOF ⽅法做故障恢复时,需要全量把
⽇志都执⾏⼀遍,⼀旦 AOF ⽇志⾮常多,势必会造成 Redis 的恢复操作缓慢。为了 解决这个问
题,Redis 增加了 RDB 快照。
所谓的快照,就是记录某⼀个瞬间东西,⽐如当我们给⻛景拍照时,那⼀个瞬间的画⾯和信息就
记录到了⼀张照⽚。所以,RDB 快照就是记录某⼀个瞬间的内存数据,记录的是实际数据,⽽
AOF ⽂件记录的是命令操作的⽇志,⽽不是实际的数据。因此在 Redis 恢复数据时, RDB 恢复数
据的效率会⽐ AOF ⾼些,因为直接将 RDB ⽂件读⼊内存就可以,不需要像 AOF 那样还需要额外
执⾏操作命令的步骤才能恢复数据。
Redis 提供了两个 命令来⽣成 RDB ⽂件,分别 是 save 和 bgsave ,他们的区别就在于是否在「主线程」⾥执⾏:
执⾏了 save 命令,就会在主线程⽣成 RDB ⽂件,由于和执⾏操作命令在同⼀个线程,所以如
果写⼊ RDB ⽂件的时间太⻓,会阻塞主线程;
执⾏了 bgsave 命令,会创建⼀个⼦进程来⽣成 RDB ⽂件,这样可以避免主线程的阻塞;
AOF 和RDB 优缺点
AOF :
优点:⾸先,AOF 提供了更好的数据安全性,因为它默认每接收到⼀个写命令就会追加到 ⽂件
末尾。即使Redis 服务器宕机,也只会丢失最后⼀次写⼊前的数据。其次,AOF ⽀持多种同步策
略(如everysec 、always 等),可以根据需要调整数 据安全性和性能之间的平衡。同时,AOF ⽂
件在Redis 启动时可以通过重写机制优化,减少⽂件体 积,加快恢复速度。并且,即使⽂件发⽣
损坏,AOF 还提供了redis-check-aof ⼯具来修复损坏的⽂件。
缺点:因为记录了每⼀个写操作,所以AOF ⽂件通常⽐RDB ⽂件更⼤,消耗更多的磁盘空间。并
且,频繁的磁盘IO 操作(尤其是同步策略设置为always 时)可能会对Redis 的写⼊性能造成⼀定
影响。⽽且,当问个⽂件体 积过⼤时,AOF 会进⾏重写操作,AOF 如果没有开启AOF 重写或者重
写频率较低,恢复过程可能较慢,因为它需要重放所有的操作命令。
RDB :
优点: RDB 通过快照的形式 保存某⼀时刻的数据状态,⽂件体 积⼩,备份和恢复的速度⾮常快。
并且,RDB 是在主线程之外通过fork ⼦进程来进⾏的,不会阻塞服务器处理命令请求,对Redis
服务的性能影响较⼩。最后,由于是定期快照,RDB ⽂件通常⽐AOF ⽂件⼩得多。
缺点: RDB ⽅式在两次快照之间,如果Redis 服务器发⽣故障,这段时间的数据将会丢失。并且,
如果在RDB 创建快 照到恢复期间有写操作,恢复后的数据可能与故障前的数据不完全⼀致
mysql 索引底层原理是什么 ?
MySQL InnoDB 引擎是⽤了B+ 树作为了 索引的数据结构。
B+Tree 是⼀种多叉树,叶⼦节点才存放数 据,⾮叶⼦节点只存放索引,⽽且每个节点⾥的数据是
按主键顺序存放的。每⼀层⽗节点的索引值都会出现在下层⼦节点的索引值中,因此在叶⼦节点
中,包括了所有的索引值信息,并且每⼀个叶⼦节点都有两个 指针,分别 指向下⼀个叶⼦节点和
上⼀个叶⼦节点,形成⼀个双向链表。
主键索引的 B+Tree 如图所⽰:

⽐如,我们执⾏了下 ⾯这条查 询语句:
select * from product where id = 5;这条语句使⽤了主 键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会⾃顶向下逐层进⾏
查找:
将 5 与根节点的索引数据 (1 ,10 ,20) ⽐较,5 在 1 和 10 之间,所以根据 B+Tree 的搜索逻
辑,找到第⼆层的索引数据 (1 ,4,7) ;
在第⼆层的索引数据 (1 ,4,7) 中进⾏查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数
据(4,5,6);在叶⼦节点的索引数据(4,5,6)中进⾏查找,然后我们找到了索引值为 5 的⾏数据。
数据库的索引和数据都是存储在硬盘的 ,我们可以把读取⼀个节点当作⼀次磁盘 I/O 操作。那么上⾯的整个查询过程⼀共经历了 3 个节点,也就是进⾏了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层⾼度就可以满⾜,这意味着从千万级的表查询⽬标数据最
多需要 3-4 次磁盘 I/O ,所以B+Tree 相⽐于 B 树和⼆叉树来说,最⼤的优势在于查询效率很⾼,
因为即使在数据量很⼤的情况,查询⼀个数据的磁盘 I/O 依然维持在 3-4 次。
怎么解决脏读和幻读?
脏读和幻读的区别 :
脏读:脏读是指⼀个事 务读取了另⼀个未提交事 务的数据。例如,事务 A 正在修改数 据但尚未
提交,事务 B 却读取了事 务 A 修改的数据。如果事务 A 后来回滚了修改,那么事 务 B 读取的数
据就是⽆效的、“脏” 的数据。
幻读:幻读是指在⼀个事 务内,多次查询同⼀数据集,但每次 查询的结果集可能因为其他事 务
的插⼊或删除操作⽽不同。⽐如,事务 A 先查询了⼀个表中有 5 条记录,在事务 A 还没结束
时,事务 B 插⼊了新的记录,当事务 A 再次查询时,发现有了新的记录,就好像出现了 “幻觉”
⼀样。
解决脏读和幻读的⽅法 - 事务隔离级别:
未提交读(Read Uncommitted ) - 会出现脏读和幻读:这是最低的隔离级别。在这个级别下,
⼀个事 务可以读取另 ⼀个未提交事 务的数据,会出现脏读、幻读以及不可重复读(⼀个事 务内
多次读取同⼀数据,结果不同,因为其他事 务修改了该数据)等问题。⼀般不建议在实际应⽤
中使⽤这个隔离级别来处理关键数据。
已提交读(Read Committed ) - 解决脏读:这个隔离级别保证⼀个事 务只能读取另 ⼀个已经提
交事 务的数据,从⽽解决了脏读问题。当事务 A 读取数据时,它只能看到其他事 务已经提交后
的结果。例如,在⼀个银⾏转账系统中,事务 A 查询账⼾余额,它只会读取已经完成(提交)
的转账交易后的余额,不会读取正在进⾏(未提交)的转账操作影响后 的余额。但在这个级别
下,幻读仍然可能出现。因为其他事 务的插⼊或删除操作在提交后,本事务再次查询时就会看
到变化 后的结果。
** 可重复读(Repeatable Read ) - 解决脏读和幻读(MySQL 默认隔离级别):** 在可重复读隔
离级别下,⼀个事 务在执⾏过程中多次读取同⼀数据,会得到相同的结果,不会受到其他事 务
对该数据修改的影响,从⽽解决了不 可重复读的问题。同时,MySQL 的 InnoDB 引擎通过多版
本并发控制(MVCC )机制来解决幻读问题。
串⾏化(Serializable ) - 最⾼隔离级别,完全避免脏读、幻读和不可重复读:在串⾏化隔离级
别下,事务是串⾏执⾏的,⼀个事 务必须等待前⼀个事 务完成后才能开始。这样就完全避免了
脏读、幻读和不可重复读的问题。例如,在⼀个售票系统中,如果采⽤串⾏化隔离级别,那么
当⼀个事 务在处理⼀张票的售卖操作时,其他事 务必须等待这个事 务完成后才能进⾏相关操
作,这样可以保 证数据的绝对⼀致性。不过,这种隔离级别的性能开销较⼤,因为它限制了并
发性能,导致系统的吞吐 量较低,只有在对数据⼀致性要求极⾼的场景下才会使 ⽤。
介绍⼀下cap 理论
CAP 原则⼜称 CAP 定理, 指的是在⼀个分布式系统中, Consistency (⼀致性)、 Availability (可⽤性)、Partition tolerance (分区容错性), 三者不可得兼

⼀致性(C) : 在分布式系统中的所有数据备份, 在同⼀时刻是否同 样的值(等同于所有节点访问同
⼀份最新的数据副本)
可⽤性(A): 在集群中⼀部分节点故障后, 集群整体是否还能响应客⼾端的读写请求(对数据更新具
备⾼可⽤性)