
Redis
字节跳动 Java ⾯试
很多同学都是 9-10 ⽉份拿到了字节意向,等了 1 个多⽉才知道具体的薪资,这⼏天字节跳动 25
届校招终于开奖了。
先说结论,从⽬前我看到的薪资情况来看,今年字节跳动的薪资和去年差 不多。
我们先来看看 ,去年 24 届字节跳动开发岗位的校招薪资:

我根据⽹络上同学们的爆料,整理了 25 届字节跳动后端开发的校招薪资情况:

ssp offer :
35k*15 + 1w 签字费,同学 bg 硕⼠ 985 ,base 上海
34k*15 + 1w 签字费,同学 bg 硕⼠ 985 ,base 北京
33k*15 + 1w 签字费,同学 bg 硕⼠双⼀流,base 北京
32k*15 + 1w 签字费,同学 bg 硕⼠ 985 ,base 深圳
sp offer :
30k*15 + 1w 签字费,同学 bg 硕⼠ 211 ,base 深圳
28k*15 + 1w 签字费,同学 bg 硕⼠ 211 ,base 北京
27k*15 + 1w 签字费,同学 bg 硕⼠ 985 ,base 珠海
普通 offer :
26k*15 + 1w 签字费 ,同学 bg 硕⼠ 985 ,base 北京
珠海 base 同学就会⽐较⾹,基本跟北京薪资差不多,没有打 8 折。
今年整体上跟去年差 不多,有⼀点⼩区别在于,后端开发的普通档 offer ⽐去年多了 1k ,今年是
26 15 ,去年是 25 15 。
不过,今年测试开发岗的普通档 offer 是 25k *15 ,会⽐后端开发岗位少 1k ,差距不是很⼤。
字节跳动招聘是偏向直接招聪明的⼈,⽽不想培养⼈,所以⾯试相对会⽐较严格,基本每⼀轮技
术⾯试都有⼿撕算法环节,不只是针对校招,包括社招也逃不了 。
之前有双⾮同学⾯字节实习,上来就扔 2 个 hard 级别的算法题给他做,这种很明显 就是劝退式⾯
试,⼤部分⼈肯定做不出来的,能做出来⾯试官也认了,好在这个同学平时算法下了 苦功夫,他
是⼿撕出来了,所以最后也进了字节实习。
但是也⻅过学历+实习较好的同学⾯字节,直接出了easy 算法题,这种明显 就是⾯试官很想招这个
同学,给了放⽔式的算法题,不过终究都还是有算法题。
这次,来分享字节跳动的校招⾯经,问⼋股⽂⽐较多,⼀共经历了⼀⼆三⾯,每⼀场⾯试的强度
还是蛮⾼,每次 都是 1 个⼩时+。
我把 这⼏场⾯试中⽐较有代表性的题⽬抽离出来给⼤家解析⼀波。
这次⾯经的考点,我简单罗列⼀下:

操作系统:进程调度
⽹络:HTTP 、HTTPS
Java :线程状态、多线程、volatile 、synchronized
Redis :数据结构、跳表、性能、场景应⽤、缓存⼀致性
MySQL :事务、隔离级别、⽇志、索引、间隙 锁、最左匹配原则
算法:每⼀轮 1 个算法
Redis
Redis 有哪些数据结构?
Redis 提供了丰 富的数据类型,常⻅的有五种数据类型:String (字符串),Hash (哈希),List
(列表),Set (集合)、Zset (有序集合)。


随着 Redis 版本的更新,后⾯⼜⽀持了四种数据类型:BitMap (2.2 版新增)、HyperLogLog (2.8
版新增)、GEO (3.2 版新增)、Stream (5.0 版新增)。Redis 五种数据类型的应⽤场景:
String 类型的应⽤场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
List 类型的应⽤场景:消息队列(但是有两个 问题:1. ⽣产者需要⾃⾏实现全局唯⼀ ID ;2. 不
能以消费组形式 消费数据)等。
Hash 类型:缓存对象、购物⻋等。
Set 类型:聚合计算(并集、交集、差集)场景,⽐如点赞、共同关注、抽奖活动等。
Zset 类型:排序场景,⽐如排⾏榜、电话和姓名排序等。
Redis 后续版本⼜⽀持四种数据类型,它们的应⽤场景如下:
BitMap (2.2 版新增):⼆值状态统计的场景,⽐如签到、判断⽤⼾登陆状态、连续签到⽤⼾总
数等;
HyperLogLog (2.8 版新增):海量数据基数统计的场景,⽐如百万级⽹⻚ UV 计数等;
GEO (3.2 版新增):存储地理位置信息的场景,⽐如滴滴 叫⻋;
Stream (5.0 版新增):消息队列,相⽐于基于 List 类型实现的消息队列,有这两个 特有的特
性:⾃动⽣成全局唯⼀消息ID ,⽀持以消费组形式 消费数据。
Zset 使⽤了什么 数据结构?
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
如果有 序集合的元素个数⼩于 128 个,并且每个元素的值⼩于 64 字节时,Redis 会使 ⽤压缩列
表作为 Zset 类型的底层数据结构;
如果有 序集合的元素不满⾜上⾯的条件,Redis 会使 ⽤跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来 实现了。
SkipList 了解吗?
链表在查找元素的时候,因为需要逐⼀查找,所以查询效率⾮常低,时间复杂度是O(N) ,于是就出现了跳表。跳表是在链表基础上改进过 来的,实现了⼀种「多层」的有序链表,这样的好处 是
能快读定位数据。
那跳表⻓什么 样呢?我这⾥举个 例⼦,下图展⽰了⼀个层级为 3 的跳表。

图中头节点有 L0~L2 三个 头指针,分别 指向了不 同层级的节点,然后每个层级的节点都通过指针
连接起来:
L0 层级共有 5 个节点,分别 是节点1、2、3、4、5;
L1 层级共有 3 个节点,分别 是节点 2、3、5;
L2 层级只有 1 个节点,也就是节点 3 。
如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,⽽使⽤了跳
表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再
往前遍历找到节点 4。
可以看到,这个查找过程就是在多个层级上跳来跳去,最后定位到元素。当数据量很⼤时,跳表
的查找复杂度就是 O(logN) 。跳表的时间复杂度是多少?
跳表中查找⼀个元素的时间复杂度为O(logn) ,空间复杂度是 O(n) 。为什么 MysSQL 不⽤ SkipList ?
B+ 树的⾼度在3层时存储的数据可能已达千万级别,但对于跳表⽽⾔同样去维护千万的数据量那么
所造成的跳表层数过⾼⽽导致的磁盘io 次数增多,也就是使⽤B+ 树在存储同样的数据下磁盘io 次数
更少。
Redis 使⽤场景?
Redis 是⼀种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度⾮常快,常
⽤于缓存,消息队列、分布式锁等场景。

Redis ⽤途
Redis 提供了多种数据类型来⽀持不同的业务场景,⽐如 String( 字符串)、Hash( 哈希)、 List ( 列
表)、Set( 集合)、Zset( 有序集合)、Bitmaps (位图)、HyperLogLog (基数统计)、GEO (地理信息)、Stream (流),并且对数据类型的操作都是原⼦性的,因为执⾏命令由单线程负责 的,不存在并发竞争的问题。除此之外,Redis 还⽀持事务 、持久化、Lua 脚本、多种集群⽅案(主从 复制模式、哨兵模式、切
⽚机群模式)、发布/订阅模式,内存淘汰机制、过期删除机制等等 。
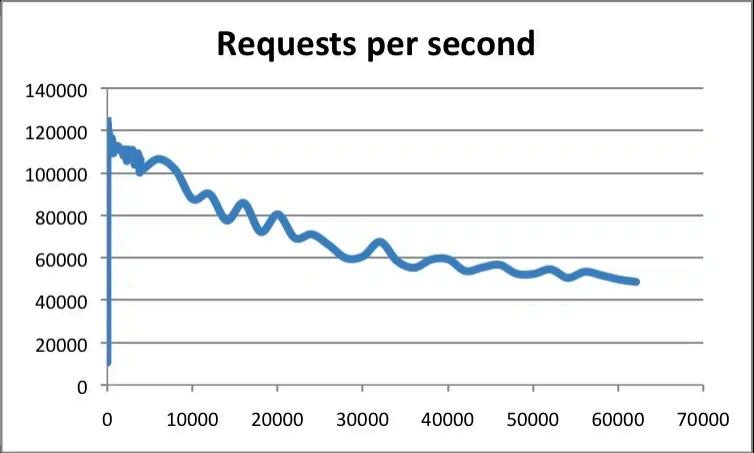
Redis 性能好的原因是什么 ?
官⽅使⽤基准测试的结果是,单线程的 Redis 吞吐 量可以达到 10W/ 每秒,如下图所⽰:
之所以 Redis 采⽤单线程(⽹络 I/O 和执⾏命令)那么快,有如下⼏个原因:
Redis 的⼤部分操作都在内存中完成,并且采⽤了⾼效的数据结构,因此 Redis 瓶颈可能是机器
的内存或者⽹络带宽,⽽并⾮ CPU ,既然 CPU 不是瓶颈,那么⾃然就采⽤单线程的解决⽅案
了;
Redis 采⽤单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的
开销,⽽且也不 会导致死锁问题。
Redis 采⽤了 I/O 多路复⽤机制处理⼤量的客⼾端 Socket 请求,IO 多路复⽤机制是指⼀个线程
处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运⾏单线程的
情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket 。内核会⼀直监听这些
Socket 上的连接请求或数据请求。⼀旦有请求到达,就会交给 Redis 线程处理,这就实现了⼀
个 Redis 线程处理多个 IO 流的效果。
Redis 和 MySQL 如何保 证⼀致性
可以采⽤「先更新数 据库,再删除缓存」的更新策略+过期时间来兜底。
我们⽤「读 + 写」请求的并发的场景来分析。
假如某个⽤⼾数据在缓存中不 存在,请求 A 读取数据时从数据库中查询到年龄为 20 ,在未写⼊缓
存中时另⼀个请求 B 更新数 据。它更新数 据库中的年龄为 21 ,并且清空缓存。这时请求 A 把从数
据库中读到的年龄为 20 的数据写⼊到缓存中。

最终,该⽤⼾年龄在缓存中是 20 (旧值),在数据库中是 21 (新值),缓存和数据库数据不⼀致。
从上 ⾯的理论上分析,先更新数 据库,再删除缓存也是会出现数据不⼀致性的问题,但是在实际
中,这个问题出现的概率并不⾼。
因为缓存的写⼊通常要远远 快于数据库的写⼊,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。
⽽⼀旦请求 A 早于请求 B 删除缓存之前更新了缓存,那么接下来的请求就会因为缓存不命中⽽从
数据库中重新读取数据,所以不会出现这种不⼀致的情况。
所以,「先更新数 据库 + 再删除缓存」的⽅案,是可以保 证数据⼀致性的。
⽽且为了 确保万⽆⼀失,还给缓存数据加上了 「过期时间」,就算在这期间存在缓存数据不⼀致,
有过期时间来兜底,这样也能达到最终⼀致。
MySQL
事务有哪些特性?
事务 4 个特性,分别 如下:
原⼦性(Atomicity ):⼀个事 务中的所有操作,要么全部完成,要么全部不完成,不会结束在
中间某个环节,⽽且事 务在执⾏过程中发⽣错误,会被回滚到事务开始前的状态,就像这个事
务从来没有执⾏过⼀样,就好⽐买⼀件商品,购买成功时,则给商家付了 钱,商品到⼿;购买
失败时,则商品在商家⼿中,消费者的钱也没花出去。
⼀致性(Consistency ):是指事务操作前和操作后,数据满⾜完整性约束,数据库保持⼀致性
状态。⽐如,⽤⼾ A 和⽤⼾ B 在银⾏分别 有 800 元和 600 元,总共 1400 元,⽤⼾ A 给⽤⼾ B
转账 200 元,分为两个 步骤,从 A 的账⼾扣除 200 元和对 B 的账⼾增加 200 元。⼀致性就是
要求上述步骤操作后,最后的结果是⽤⼾ A 还有 600 元,⽤⼾ B 有 800 元,总共 1400 元,⽽
不会出现⽤⼾ A 扣除了 200 元,但⽤⼾ B 未增加的情况(该情况,⽤⼾ A 和 B 均为 600 元,
总共 1200 元)。
隔离性(Isolation ):数据库允许多个并发事务同时对其数据进⾏读写和修改的能⼒,隔离性可
以防⽌多个事 务并发执⾏时由于交 叉执⾏⽽导致数据的不⼀致,因为多个事 务同时使⽤相同的
数据时,不会相互⼲扰,每个事 务都有⼀个完整的数据空间,对其他并发事务是隔离的。也就
是说,消费者购买商品这个事 务,是不影响其他消费者购买的。
持久性(Durability ):事务处理结束后,对数据的修改就是永久的,即便系统故障也不 会丢
失。
隔离性有哪些隔离级别?
四个隔离级别如下:
读未提交(*read uncommitted* ),指⼀个事 务还没提交时,它做的变更就能被其他事 务看到;
读提交(read committed ),指⼀个事 务提交之 后,它做的变更才能被其他事 务看到;
可重复读(repeatable read ),指⼀个事 务执⾏过程中看到的数据,⼀直跟这个事 务启动时看
到的数据是⼀致的,MySQL InnoDB 引擎的默认隔离级别;
串⾏化(*serializable* );会对记录加上读写锁,在多个事 务对这条记录进⾏读写操作时,如果发⽣了读写冲 突的时候,后访问的事务必须等前⼀个事 务执⾏完成,才能继续执⾏;
按隔离⽔平⾼低排序如下:

针对不同的隔离级别,并发事务时可能发⽣的现象也会不同。

也就是说:
在「读未提交」隔离级别下,可能发⽣脏读、不可重复读和幻读现象;
在「读提交」隔离级别下,可能发⽣不可重复读和幻读现象,但是不可能发⽣脏读现象;
在「可重复读」隔离级别下,可能发⽣幻读现象,但是不可能脏 读和不可重复读现象;
在「串⾏化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发⽣。
MySQL 默认⽤的哪个级别?
MySQL 默认隔离级别是「可重复读」,可以很⼤程度上避免幻读现象的发⽣(注意是很⼤程度避
免,并不是彻底避免),所以 MySQL 并不会使 ⽤「串⾏化」隔离级别来避免幻读现象的发⽣,因
为使⽤「串⾏化」隔离级别会影响性能。
间隙 锁的原理
Gap Lock 称为间隙 锁,只存在于可重复读隔离级别,⽬的是为了 解决可重复读隔离级别下幻读的
现象。
假设,表中有⼀个范围 id 为(3,5)间隙 锁,那么其他事 务就⽆法插⼊ id = 4 这条记录了,这样就有效的防⽌幻读现象的发⽣。

间隙 锁虽然存在 X 型间隙 锁和 S 型间隙 锁,但是并没有什么 区别,间隙 锁之间是兼容的,即两个 事务可以同时持有包含共同间隙 范围的间隙 锁,并不存在互斥关系,因为间隙 锁的⽬的是防⽌插
⼊幻影记录⽽提出的。
什么 时候会加间隙 锁?
当我们⽤唯⼀索引进⾏等值查询的时候,查询的记录不存在的时候,在索引树找到第⼀条⼤于该
查询记 录的记录后,将该记 录的索引中的 next-key lock 会退化成「间隙 锁」。
假设事务 A 执⾏了这条等值查询语句,查询的记录是「不存在」于表中的。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id = 2 for update;
Empty set (0.03 sec)
接下来,通过 select * from performance_schema.data_locks\G; 这条语句,查看事务执⾏ SQL过程中加了什么 锁。

从上 图可以看到,共加了两个 锁,分别 是:
表锁:X 类型的意向锁;
⾏锁:X 类型的间隙 锁;

因此,此时事务 A 在 id = 5 记录的主键索引上加的是间隙 锁,锁住的范围是 (1, 5) 。接下来,如果有 其他事 务插⼊ id 值为 2、3、4 这⼀些记录的话,这些插⼊语句都会发⽣阻塞。
注意,如果其他事 务插⼊的 id = 1 或者 id = 5 的记录话,并不会发⽣阻塞,⽽是报主键冲突的错
误,因为表中已经存在 id = 1 和 id = 5 的记录了。⽐如,下⾯这个例⼦:

因为事 务 A 在 id = 5 记录的主键索引上加了范围为 (1, 5) 的 X 型间隙 锁,所以事务 B 在插⼊⼀条
id 为 3 的记录时会被阻塞住,即⽆法插⼊ id = 3 的记录。MySQL 如何保 证原⼦性?
通过 undo log 来保证原⼦性的。
undo log 是⼀种⽤于撤销回退的⽇志。在事务没提交之 前,MySQL 会先记录更新前的数据到
undo log ⽇志⽂件⾥⾯,当事务回滚时,可以利⽤ undo log 来进⾏回滚。如下图:

回滚事务
undo log 撤销过程具体是怎么撤销的?
每当 InnoDB 引擎对⼀条记录进⾏操作(修改、删除、新增)时,要把回滚时需要的信息都记录到
undo log ⾥,⽐如:
在插⼊⼀条记录时,要把这条记录的主键值记下来,这样之后回滚时只需要把这个主 键值对应
的记录删掉就好了;
在删除⼀条记录时,要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的
记录插⼊到表中就好了;
在更新⼀条记录时,要把被更新的列的旧值记下来,这样之后回滚时再把这些列更新为旧值就
好了。
在发⽣回滚时,就读取 undo log ⾥的数据,然后做原先相反操作。⽐如当 delete ⼀条记录时,
undo log 中会把记录中的内容都记下来,然后执⾏回滚操作的时候,就读取 undo log ⾥的数据,
然后进⾏ insert 操作。
怎么决定建⽴哪些索引?
什么 时候适⽤索引?
字段有唯⼀性限制的,⽐如商品编码;
经常⽤于 WHERE 查询条件的字段,这样能够提⾼整个表的查询速度,如果查 询条件不是⼀个
字段,可以建⽴联合索引。
经常⽤于 GROUP BY 和 ORDER BY 的字段,这样在查询的时候就不需要再去做⼀次排序了,因
为我们都已经知道了建⽴索引之后在 B+Tree 中的记录都是排序好的。
什么 时候不需要创建索引?
WHERE 条件, GROUP BY , ORDER BY ⾥⽤不到的字段,索引的价值是快速定位,如果起不到
定位的字段通常是不需要创建索引的,因为索引是会占⽤物理空间的。
字段中存在⼤量重 复数据,不需要创建索引,⽐如性别字段,只有男⼥,如果数据库表中,男
⼥的记录分布均匀,那么⽆论搜索哪个值都可能得到⼀半的数据。在这些情况下,还不如不要
索引,因为 MySQL 还有⼀个查询优化器, 查询优化器发现某个值出现在表的数据⾏中的百 分⽐
很⾼的时候,它⼀般会忽略索引,进⾏全表扫描。
表数据太少的时候,不需要创建索引;
经常更新的字段不⽤创建索引,⽐如不要对电商项⽬的⽤⼾余额建⽴索引,因为索引字段频繁
修改,由
最左匹配是什么 ,举个 例⼦?
使⽤联合索引时,存在最左匹配原则,也就是按照最左优先的⽅式进⾏索引的匹配。在使⽤联合
索引进⾏查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就⽆法利⽤到索引快
速查询的特性了。
⽐如,如果创建了⼀个 (a, b, c) 联合索引,如果查 询条件是以下这⼏种,就可以匹配上联合索引:
where a=1 ;
where a=1 and b=2 and c=3 ;
where a=1 and b=2 ;
需要注意的是,因为有查 询优化器, 所以 a 字段在 where ⼦句的顺序并 不重要。但是,如果查 询条件是以下这⼏种,因为不 符合最左匹配原则,所以就⽆法匹配上联合索引,联
合索引就会失效:
where b=2 ;
where c=3 ;
where b=2 and c=3 ;
上⾯这些查询条件之所以会 失效,是因为 (a, b, c) 联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再 按 c 排序。所以,b 和 c 是全局⽆序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是⽆法利⽤到索引的。
我这⾥举联合索引(a,b)的例⼦,该联合索引的 B+ Tree 如下(图中叶⼦节点之间我画了单向
链表,但是实际上是双向链表,原图我找 不到了,修改不了 ,偷个懒我不重画了,⼤家脑补成双
向链表就⾏)。

可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8 ),⽽ b 是全局是⽆序的(12 ,7,8,2,3,
8,10 ,5,2)。因此,直接执⾏ where b = 2 这种查询条件没有办法利⽤联合索引的,利⽤索引的前提是索引⾥的 key 是有序的。
只有在 a 相同的情况才,b 才是有序的,⽐如 a 等于 2 的时候,b 的值为(7,8),这时就是有序
的,这个有序状态是局部的,因此,执⾏ where a = 2 and b = 7 是 a 和 b 字段能⽤到联合索引的,也就是联合索引⽣效了。
Java
Java ⾥⾯线程有哪些状态?

源⾃《Java 并发编程艺术》
java.lang.Thread.State 枚举类中定义了 六种线程的状态,可以调⽤线程Thread 中的


getState() ⽅法获取当前线程的状态。wait 状态下的线程如何进⾏恢复到 running 状态?
等待的线程被其他线程对象唤醒, notify() 和 notifyAll() 。如果线程没有获取到锁则会直接进⼊ Waiting 状态,其实这种本质上它就是执⾏了
LockSupport.park() ⽅法进⼊了Waiting 状态,那么解锁的时候会执⾏
LockSupport.unpark(Thread) ,与上 ⾯park ⽅法对应,给出许可证,解除等待状态。notify 和 notifyAll 的区别?
同样是唤醒等待的线程,同样最多只有⼀个线程能获得锁,同样不能控制哪个线程获得锁。
区别在于:
notify :唤醒⼀个线程,其他线程依然处于wait 的等待唤醒状态,如果被唤醒的线程结束时没调
⽤notify ,其他线程就永远没⼈去唤醒,只能等待超时,或者被中断
notifyAll :所有线程退出wait 的状态,开始竞争锁,但只有⼀个线程能抢到,这个线程执⾏完
后,其他线程⼜会有⼀个幸运⼉脱颖⽽出得到锁
notify 选择哪个线程?
notify 在源码的注释中说到notify 选择唤醒的线程是任意的,但是依赖于具体实现的jvm 。

notify 源码
JVM 有很多实现,⽐较流⾏的就是hotspot ,hotspot 对notofy() 的实现并不是我们以 为的随机唤醒,,⽽是“先进先出”的顺序唤醒。
如何停⽌⼀个线程的运⾏?
主要有这些⽅法:
异常法停⽌:线程调⽤interrupt() ⽅法后,在线程的run ⽅法中判断当前对象的interrupted() 状态,如果是中断状态则抛出异常,达到中断线程的效果。
在沉睡中停⽌:先将线程sleep ,然后调⽤interrupt 标记中断状态,interrupt 会将阻塞状态的线
程中断。会抛出中断异常,达到停⽌线程的效果
stop() 暴⼒停⽌:线程调⽤stop() ⽅法会被暴⼒停⽌,⽅法已弃⽤,该⽅法会有不好的后果:强制让线程停⽌有可能使⼀些请理性的⼯作得不到完成。
使⽤return 停⽌线程:调⽤interrupt 标记为中 断状态后,在run ⽅法中判断当前线程状态,如果
为中 断状态则return ,能达到停⽌线程的效果。
调⽤ interrupt 是如何让线程抛出异常的?
每个线程都⼀个与之 关联的布尔属 性来表⽰其中断状态,中断状态的初始值为false ,当⼀个线程
被其它线程调⽤ Thread.interrupt() ⽅法中断时,会根据实际情况做出响应。
如果该线程正在执⾏低级别的可中断⽅法(如 Thread.sleep() 、 Thread.join() 或
Object.wait() ),则会解除阻 塞并抛出 **InterruptedException** 异常。
否则 Thread.interrupt() 仅设置线程的中断状态,在该被中断的线程中稍后可 通过轮 询中断状态来决定是否要停⽌当前正在执⾏的任务。
如果是靠变量来停⽌线程,缺点是什么 ?
缺点是中断可能不够及时,循环判断时会到下⼀个循环才能判断出来。
class InterruptFlag { // 自定义的中断标识符
private static volatile boolean isInterrupt = false; public static void main(String[] args) throws InterruptedException { // 创建可中断的线程实例
Thread thread = new Thread(() -> { while (!isInterrupt) { // 如果 isInterrupt=true 则停止线程
System.out.println("thread 执行步骤 1:线程即将进入休眠状态 "); try { // 休眠 1s
e.printStackTrace();
}
System.out.println("thread 执行步骤2:线程执行了任务");
}
});
thread.start(); // 启动线程
// 休眠 100ms,等待 thread 线程运行起来
Thread.sleep(100);
System.out.println("主线程:试图终止线程 thread");
// 修改中断标识符,中断线程
isInterrupt = true;
}
}当终⽌线程后,执⾏步骤2依然会被执⾏,这就是缺点。
volatile 保证原⼦性吗?
volatile 关键字并没有保证我们的变量的原⼦性,volatile 是Java 虚拟机提供的⼀种轻量级的同步机
制,主要有这三个 特性:
保证可⻅性
不保证原⼦性
禁⽌指令重排
那我们要如何保 证原⼦性?
可以通过synchronized 来保证原⼦性。
synchronized ⽀持重⼊吗?如何实现的?
synchronized 是基于原⼦性的内部锁机制,是可重⼊的,因此在⼀个线程调⽤synchronized ⽅法的
同时在其⽅法体内部调⽤该对象另⼀个synchronized ⽅法,也就是说⼀个线程得到⼀个对象锁后再
次请求该对象锁,是允许的,这就是synchronized 的可重⼊性。
synchronized 底层是利⽤计算机系统mutex Lock 实现的。每⼀个可重⼊锁都会关联⼀个线程ID 和⼀个锁状态status 。
当⼀个线程请求⽅法时,会去检查锁状态。
如果锁状态是0,代表该锁没有被占⽤,使⽤CAS 操作获取锁,将线程ID 替换成⾃⼰的线程ID 。
如果锁状态不是0,代表有线程在访问该⽅法。此时,如果线程ID 是⾃⼰的线程ID ,如果是可重
⼊锁,会将status ⾃增1,然后获取到该锁,进⽽执⾏相应的⽅法;如果是⾮重⼊锁,就会进⼊
阻塞队列等待。
在释放锁时,
如果是可重⼊锁的,每⼀次退出⽅法,就会将status 减1,直⾄status 的值为0,最后释放该锁。
如果⾮可重⼊锁的,线程退出⽅法,直接就会释放该锁。
⽹络
HTTP 与 HTTPS 协议的区别?

HTTP 与 HTTPS ⽹络层
HTTP 是超⽂本传输协议,信息是明 ⽂传输,存在安全⻛险的问题。HTTPS 则解决 HTTP 不安全
的缺陷,在 TCP 和 HTTP ⽹络层之间加⼊了 SSL/TLS 安全协议,使得报⽂能够加密传输。
HTTP 连接建⽴相对简单, TCP 三次握⼿之后便可进⾏ HTTP 的报⽂传输。⽽ HTTPS 在 TCP 三
次握⼿之后,还需进⾏ SSL/TLS 的握⼿过程,才可进⼊加密报⽂传输。
两者的默认端⼝不⼀样,HTTP 默认端⼝号是 80 ,HTTPS 默认端⼝号是 443 。
HTTPS 协议需要向 CA (证书权威机构 )申请数字证书,来保证服务器的⾝份是可信的。
操作系统
有哪些进程调度算法 ?
01 先来先服务调度算法
最简单的⼀个调度算法,就是⾮抢占式的先来先服务(First Come First Serve, FCFS )算法了。

FCFS 调度算法
顾名思义,先来后到,每次 从就绪队列选择最先进⼊队列的进程,然后⼀直运⾏,直到进程退出
或被阻塞,才会继续从队列中选择第⼀个进程接着运⾏。
这似乎很公平,但是当⼀个⻓作业先运⾏了,那么后⾯的短作业等待的时间就会很⻓,不利于短
作业。
FCFS 对⻓作业有利,适⽤于 CPU 繁忙型作业的系统,⽽不适⽤于 I/O 繁忙型作业的系统。
02 最短作业优先调度算法
最短作业优先(*Shortest Job First, SJF* )调度算法同样也是顾名思义,它会优先选择运⾏时间最短的进程来运⾏,这有助于提⾼系统的吞吐 量。

SJF 调度算法
这显然对⻓作业不 利,很容易造成⼀种极端现象。
⽐如,⼀个⻓作业在就绪队列等待运⾏,⽽这个就绪队列有⾮常多的短作业,那么就会使 得⻓作
业不 断的往后推,周转时间变⻓,致使⻓作业⻓期不会被运⾏。
03 ⾼响应⽐优先调度算法
前⾯的「先来先服务调度算法」和「最短作业优先调度算法」都没有很好的权衡短作业和⻓作
业。
那么,⾼响应⽐优先 (*Highest Response Ratio Next, HRRN* )调度算法主要是权衡了短作业和⻓作业。
每次 进⾏进程调度时,先计算「响应⽐优先级」,然后把「响应⽐优先级」最⾼的进程投⼊运⾏,
「响应⽐优先级」的计算公式:

从上 ⾯的公式,可以发现:
如果两个 进程的「等待时间」相同时,「要求的服务时间」越短,「响应⽐」就越⾼,这样短作
业的进程容易被选中运⾏;
如果两个 进程「要求的服务时间」相同时,「等待时间」越⻓,「响应⽐」就越⾼,这就兼顾到
了⻓作业进程,因为进程的响应⽐可以随时间等待的增加⽽提⾼,当其等待时间⾜够⻓时,其
响应⽐便可以升到很⾼,从⽽获得运⾏的机会;
04 时间⽚轮转 调度算法

最古⽼、最简单、最公平且使⽤最⼴的算法就是时间⽚轮转 (Round Robin, RR )调度算法。
RR 调度算法
每个进程被分配⼀个时间段,称为时间⽚(*Quantum* ),即允许该 进程在该时间段中运⾏。如果时间⽚⽤完,进程还在运⾏,那么将会把此进程从 CPU 释放出来,并把 CPU 分配给另外
⼀个进程;
如果该进程在时间⽚结束前阻塞或结束,则 CPU ⽴即进⾏切换;
另外,时间⽚的⻓度就是⼀个很关键的点:
如果时间⽚设得太短会导致过多的进程上下 ⽂切换,降低了 CPU 效率;
如果设得太⻓⼜可能引起对短作业进程的响应时间变⻓。将
⼀般来说,时间⽚设为 20ms~50ms 通常是⼀个⽐较合理的折中值。
05 最⾼优先级调度算法
前⾯的「时间⽚轮转 算法」做了个 假设,即让所有的进程同等重要,也不 偏袒谁,⼤家的运⾏时
间都⼀样。
但是,对于多⽤⼾计算机系统就有不同的看法了,它们希望调度是有优先级的,即希望调度程序
能从就绪队列中选择最⾼优先级的进程进⾏运⾏,这称为最⾼优先级(*Highest Priority First ,
HPF* )调度算法。进程的优先级可以分为,静态优先级和动态优先级:
静态优先级:创建进程时候,就已经确定了优先级了,然后整个运⾏时间优先级都不会变化 ;
动态优先级:根据进程的动态变化 调整优先级,⽐如如 果进程运⾏时间增加,则降低其优先
级,如果进程等待时间(就绪队列的等待时间)增加,则升⾼其优先级,也就是随着时间的推
移增加等待进程的优先级。
该算法也有两种处理优先级⾼的⽅法,⾮抢占式和抢占式:
⾮抢占式:当就绪队列中出现优先级⾼的进程,运⾏完当前进程,再选择优先级⾼的进程。
抢占式:当就绪队列中出现优先级⾼的进程,当前进程挂起,调度优先级⾼的进程运⾏。
但是依然有缺点,可能会导致低优 先级的进程永远不会运⾏。
06 多级反馈队列调度算法
多级反馈队列(Multilevel Feedback Queue )调度算法是「时间⽚轮转 算法」和「最⾼优先级
算法」的综合和 发展。
顾名思义:
「多级」表⽰有多个队列,每个队列优先级从⾼到低,同时优先级越⾼时间⽚越短。
「反馈」表⽰如果有 新的进程加⼊优先级⾼的队列时,⽴刻停⽌当前正在运⾏的进程,转⽽去
运⾏优先级⾼的队列;

多级反馈队列
来看看 ,它是如何⼯作的:
设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从⾼到低,同时优先级越⾼时
间⽚越短;
新的进程会被放⼊到第⼀级队列的末尾,按先来先服务的原则排队等待被调度,如果在第⼀级
队列规定的时间⽚没运⾏完成,则将其转⼊到第⼆级队列的末尾,以此类推,直⾄完成;
当较⾼优先级的队列为空,才调度较低优 先级的队列中的进程运⾏。如果进程运⾏时,有新进
程进⼊较⾼优先级的队列,则停⽌当前运⾏的进程并将其移⼊到原队列末尾,接着让较⾼优先
级的进程运⾏;
可以发现,对于短作业可能可以在第⼀级队列很快 被处理完。对于⻓作业,如果在第⼀级队列处
理不完,可以移⼊下次队列等待被执⾏,虽然等待的时间变⻓了,但是运⾏时间也变更⻓了,所
以该算法很好的兼顾了⻓短作业,同时有较好的响应时间。
算法
给定链表 1 -> 2 -> ... -> n-1 -> n ,使⽤ O(1) 空间复杂度使其变为 1 -> n -> 2 -> n-1 -> ...