
项⽬
⽶哈游 Java ⾯试
今天来分享⼀位同学⽶哈游的⾯经,投递的岗位是云原⽣,同学是校招⽣没有云原⽣的基础,所
以⾯试没有问云原⽣的内容,但是都在计算机基础⽅⾯的内容,都是经典的⾯试问题。
不管是⾯后端开发、客⼾端开发、测试开发等岗位,计算机基础的内容都逃不开的,包括社招⾯
⼤⼚,即使⼯作了好⼏年,也会问考察⼀些计算机基础的问题,所以同学们⼀定要好好 掌握 。

这个⾯试难在的是在算法, 抽五星卡概率,不愧是游戏⼤⼚,出的题⽬也是游戏背景。
操作系统
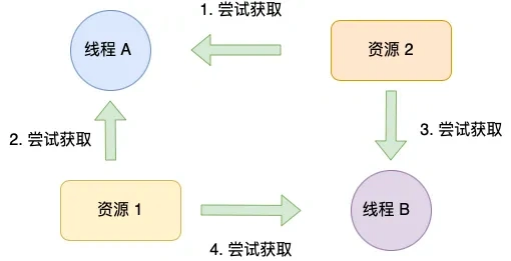
死锁发⽣条件是什么 ?
死锁只有同时满⾜以下四个条件才会发⽣:
互斥条件:互斥条件是指多个线程不能同时使⽤同⼀个资源。
持有并等待条件:持有并等待条件是指,当线程 A 已经持有了资源 1,⼜想申请资源 2,⽽资
源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时
并不会释放⾃⼰已经持有的资源 1。
不可剥夺条件:不可剥夺条件是指,当线程已经持有了资源 ,在⾃⼰使⽤完之前不能被其他线
程获取,线程 B 如果也想使⽤此资源,则只能在线程 A 使⽤完并释放后才能获取。
环路等待条件:环路等待条件指的是,在死锁发⽣的时候,两个 线程获取资源的顺序构成了环
形链。
如何避免死锁?
避免死锁问题就只需要破环其中⼀个条件就可以,最常⻅的并且可⾏的就是使⽤资源有序分配
法,来破环环 路等待条件。
那什么 是资源有序分配法呢?线程 A 和 线程 B 获取资源的顺序要⼀样,当线程 A 是先尝试获取资
源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也
就是说,线程 A 和 线程 B 总是以相同的顺序申请⾃⼰想要的资源。
介绍⼀下操作系统内存管理
操作系统设计 了虚拟内存,每个进程都有⾃⼰的独⽴的虚拟内存,我们所写的程序不会直接与物
理内打交道。

有了虚拟内存之后,它带来了这些好处 :
第⼀,虚拟内存可以使 得进程对运⾏内存超过物理内存⼤⼩,因为程序运⾏符合局部性原理,
CPU 访问内存会有很明显 的重复访问的倾向性,对于那些没有被经常使⽤到的内存,我们可以
把它换出到 物理内存之外,⽐如硬盘上的 swap 区域。
第⼆,由于每个进程都有⾃⼰的⻚表,所以每个进程的虚拟内存空间就是相互独⽴的。进程也
没有办法访问其他进程的⻚表,所以这些⻚表是私有的,这就解决了多进程之间地址 冲突的问
题。
第三,⻚表⾥的⻚表项中除了物理地址 之外,还有⼀些标记属性的⽐特,⽐如控制⼀个⻚的读
写权限,标记该 ⻚是否存在等。在内存访问⽅⾯,操作系统提供了更好的安全性。
Linux 是通过对内存分⻚的⽅式来管理内存,分⻚是把整个虚拟和物理内存空间切成⼀段段 固定尺
⼨的⼤⼩。这样⼀个连续并且尺⼨固定的内存空间,我们叫⻚(Page )。在 Linux 下,每⼀⻚的⼤
⼩为 4KB 。
虚拟地址 与物理地址 之间通过⻚表来映射,如下图:

⻚表是存储在内存⾥的,内存管理单元 (MMU )就做将虚拟内存地址 转换成物理地址 的⼯作。
⽽当进程访问的虚拟地址在 ⻚表中查不到时,系统会产⽣⼀个缺⻚异常,进⼊系统内核空间分配
物理内存、更新进程⻚表,最后再返回⽤⼾空间,恢复进程的运⾏。
介绍copy on write
主进程在执⾏ fork 的时候,操作系统会把主进程的「⻚表」复制⼀份给⼦进程,这个⻚表记录着
虚拟地址 和物理地址 映射关系,⽽不会复制物理内存,也就是说,两者的虚拟空间不同,但其对
应的物理空间是同⼀个。
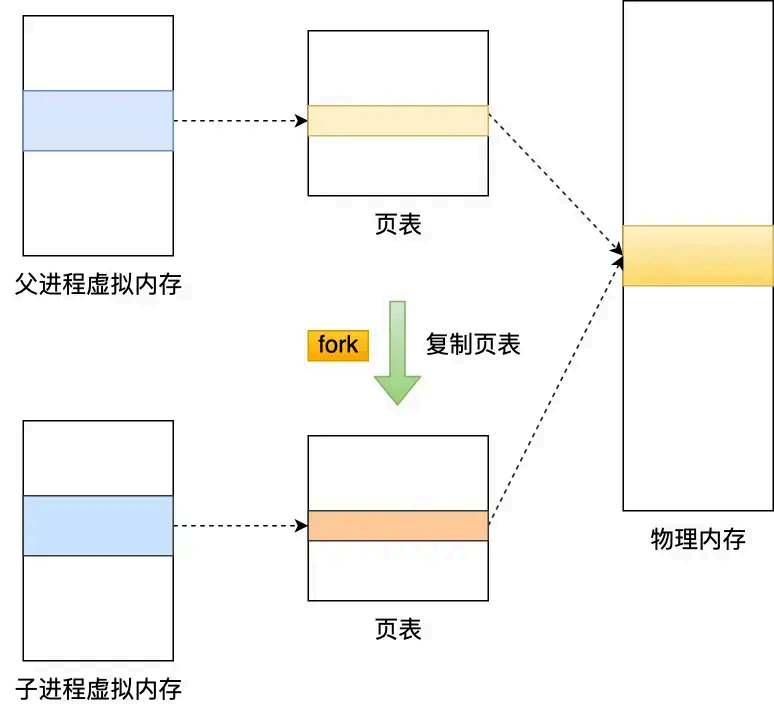
这样⼀来,⼦进程就共享了 ⽗进程的物理内存数据了,这样能够节约物理内存资源,⻚表对应的
⻚表项的属性会标记该 物理内存的权限为只读。
不过,当⽗进程或者⼦进程在向这个内存发起写操作时,CPU 就会触发写保护中断,这个写保护
中断是由于违反权限导致的,然后操作系统会在「写保护中断处理函数」⾥进⾏物理内存的复
制,并重新设置其内 存映射关系,将⽗⼦进程的内存读写权限设置为可读写,最后才会对内存进
⾏写操作,这个过程被称为「写时复制(Copy On Write )」。写时复制顾名思义,在发⽣写操作的时候,操作系统才会去复制物理内存,这样是为了 防⽌ fork
创建⼦进程时,由于物理内存数据的复制时间过⻓⽽导致⽗进程⻓时间阻 塞的问题。
copy on write 节省了什么 资源
节省了物理内存的资源,因为 fork 的时候,⼦进程不需要复制⽗进程的物理内存,避免了不 必要
的内存复制开销,⼦进程只需要复制⽗进程的⻚表,这时候⽗⼦进程的⻚表指向的都是共享的物
理内存。
只有当⽗⼦进程任何 有⼀⽅对这⽚共享的物理内存发⽣了修改操作,才会触发写时复制机制,这
时候才会复制发⽣修改操作的物理内存。
线程和进程区别

本质区别:进程是操作系统资源分配的基本单位,⽽线程是任务调度和执⾏的基本单位
在开销⽅⾯:每个进程都有独⽴的代码和数据空间(程序上下 ⽂),程序之间的切换会有较⼤的
开销;线程可以看做轻量级的进程,同⼀类线程共享代码和数据空间,每个线程都有⾃⼰独⽴
的运⾏栈和程序计数器( PC ),线程之间切换的开销⼩
稳定性⽅⾯:进程中某个线程如果崩溃了,可能会导致整个进程都崩溃。⽽进程中的⼦进程崩
溃,并不会影响其他进程。
内存分配⽅⾯:系统在运⾏的时候会为每个进程分配不同的内存空间;⽽对线程⽽⾔,除了
CPU 外,系统不会为线程分配内存(线程所使⽤的资源来⾃其所属进程的资源),线程组之间只
能共享资源
包含关系:没有线程的进程可以看做是单线程的,如果⼀个进程内有多个线程,则执⾏过程不
是⼀条线的,⽽是多条线(线程)共同完成的;线程是进程的⼀部分,所以线程也被称为轻权
进程或者轻量级进程
线程切换为什么 ⽐进程切换快,节省了什么 资源?
线程切换⽐进程切换快是因为线程共享同⼀进程的地址 空间和资源,线程切换时只需切换堆栈和
程序计数器等少量信息,⽽不需要切换地址 空间,避免了进程切换时需要切换内存映射表等⼤量
资源的开销,从⽽节省了时间和系统资源。
linux 如何查看进程状态?
可以通过 ps 命令或者 top 命令来查 看进程的状态。
⽐如我想看 nginx 进程的状态,可以在 linux 输⼊这条命令:

top 命令除了能看进程的状态,还能看到系统的信息,⽐如系统负载、内存、cpu 使⽤率等等

linux 如何查看线程状态?
在 ps 和 top 命令加⼀下参数,就能看到线程状态了:
top -H

ps -eT | grep <进程名或线程名 >⽹络
如何查看⽹络连接情况?
可以通过 netstat 命令来查 看⽹络连接的情况,⽐如下⾯,我通过 命令:
netstat -napt

显⽰了服务器上的 tcp 连接状态,可以观察到每⼀个 tcp 连接的状态,以及四元组信息(源 ip 地址、⽬标 ip 地址 ,源端⼝、源 ip )
tcp 连接过程?

⼀开始,客⼾端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端⼝,处于 LISTEN 状
态
客⼾端会随机初始化序号(client_isn ),将此序号置于 TCP ⾸部的「序号」字段中,同时把
SYN 标志位置为 1,表⽰ SYN 报⽂。接着把第⼀个 SYN 报⽂发送给服务端,表⽰向服务端发起
连接,该报⽂不包含应⽤层数据,之后客⼾端处于 SYN-SENT 状态。
服务端收到客⼾端的 SYN 报⽂后,⾸先服务端也随机初始化⾃⼰的序号(server_isn ),将此序
号填⼊ TCP ⾸部的「序号」字段中,其次把 TCP ⾸部的「确认应答号」字段填⼊ client_isn + 1,接着把 SYN 和 ACK 标志位置为 1。最后把该报⽂发给客⼾端,该报⽂也不 包含应⽤层数据,之
后服务端处于 SYN-RCVD 状态。
客⼾端收到服务端报⽂后,还要向服务端回应最后⼀个应答报⽂,⾸先该应答报⽂ TCP ⾸部
ACK 标志位置为 1 ,其次「确认应答号」字段填⼊ server_isn + 1 ,最后把报 ⽂发送给服务
端,这次报⽂可以携带客⼾到服务端的数据,之后客⼾端处于 ESTABLISHED 状态。
服务端收到客⼾端的应答报⽂后,也进⼊ ESTABLISHED 状态。
server a 和server b ,如何判断两个 服务器正常连接?出错怎么办?
直不会发送数据给客⼾端,那么服务端是永远⽆法感知到客⼾端宕机这个事 件的,也就是服务端
的 TCP 连接将⼀直处于 ESTABLISH 状态,占⽤着系统资源。
为了 避免这种情况,TCP 搞了个 保活机制。这个机制的原理是这样的:定义⼀个时间段,在这个时
间段内,如果没有任何 连接相关的活动,TCP 保活机制会开始作⽤,每隔⼀个时间间隔 ,发送⼀个
探测报⽂,该探测报⽂包含的数据⾮常少,如果连续⼏个探测报⽂都没有得到响应,则认为当前
的 TCP 连接已经死亡,系统内核将错误信息通知给上层应⽤程序。
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔 ,以下
都为默认值:
net.ipv4.tcp_keepalive_time =7200
net.ipv4.tcp_keepalive_intvl =75
net.ipv4.tcp_keepalive_probes =9
tcp_keepalive_time=7200 :表⽰保活时间是 7200 秒(2⼩时),也就 2 ⼩时内如果没有任何 连接相关的活动,则会启动保活机制
tcp_keepalive_intvl=75 :表⽰每次 检测间隔 75 秒;
tcp_keepalive_probes=9 :表⽰检测 9 次⽆响应,认为对⽅是不可达的,从⽽中断本次的连接。也就是说在 Linux 系统中,最少需要经过 2 ⼩时 11 分 15 秒才可以发现⼀个「死亡」连接。

注意,应⽤程序若想使⽤ TCP 保活机制需要通过 socket 接⼝设置 SO_KEEPALIVE 选项才能够⽣
效,如果没有设置,那么就⽆法使⽤ TCP 保活机制。
如果开启了 TCP 保活,需要考虑以下⼏种情况:
第⼀种,对端程序是正常⼯作的。当 TCP 保活的探测报⽂发送给对端, 对端会正常响应,这样
TCP 保活时间会被重置,等待下⼀个 TCP 保活时间的到来。
第⼆种,对端主机宕机并重启。当 TCP 保活的探测报⽂发送给对端后,对端是可以响应的,但
由于没有该连接的有效信息,会产⽣⼀个 RST 报⽂,这样很快 就会发现 TCP 连接已经被重置。
第三种,是对端主机宕机(注意不是进程崩溃,进程崩溃后操作系统在回收进程资源的时候,会发送 FIN 报⽂,⽽主机宕机则是⽆法感知的,所以需要 TCP 保活机制来探测对⽅是不是发⽣了主 机宕机),或对端由于其他原因导致报⽂不可达。当 TCP 保活的探测报⽂发送给对端后,⽯沉⼤海,没有响应,连续⼏次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
TCP 保活的这个机制检测的时间是有点⻓,我们可以⾃⼰在应⽤层实现⼀个⼼跳机制。
⽐如,web 服务软件⼀般都会提供 keepalive_timeout 参数,⽤来指定 HTTP ⻓连接的超时时 间。
如果设置了 HTTP ⻓连接的超时时 间是 60 秒,web 服务软件就会启动⼀个定时器,如果客⼾端在
完成⼀个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间⼀到,就会触发回调函
数来释放该连接。

项⽬
因为项⽬写了 raft 分布式 kv 的项⽬,问了⼀下 raft 算法相关的问题
⼀致性是怎么保证的
leader 选举过程是怎么样的?
leader 崩溃后重新加⼊如何保 证⽇志⼀致
⼿撕
给了⼀道go 相关题⽬,看打印出什么 ,关于append 的
hard 算法:抽五星卡概率,给了个 思路,没写出来,⽬测gg 了