
15.Linux 命令
15.Linux 命令
Linux 的常用命令了解过哪些?
文件相关(mv mkdir cd ls)
进程相关( ps top netstate )
权限相关(chmod chown useradd groupadd)
网络相关(netstat ip addr)
测试相关(测试网络连通性:ping 测试端口连通性:telnet)ps 命令里都有哪些选项,ps 展示哪些东 西?
ps 命令展示内容:

PID :进程ID 。
PPID :父进程ID 。
USER :进程所属用户。
%CPU :CPU 占用率。
%MEM :内存占用率。
VSZ :虚拟内存大小。
RSS :物理内存大小。
TTY :终端设备。
STAT :进程状态。
START :进程启动时间。
TIME :进程累计CPU 占用时间。
COMMAND :进程命令或可执行文件。
ps 命令选项:
-a :显示所有进程,包括其他用户的进程。
-u :显示用户相关的进程信息。
-x :显示没有控制终端的进程。
-e :显示所有进程,等同于-a 选项。
-f :显示详细的进程信息,包括进程的父进程、运行状态等。
-l :显示长格式的进程信息,包括进程的PID 、PPID 、CPU 占用率等。
-r :显示正在运行的进程。
-o :自定义输出格式。
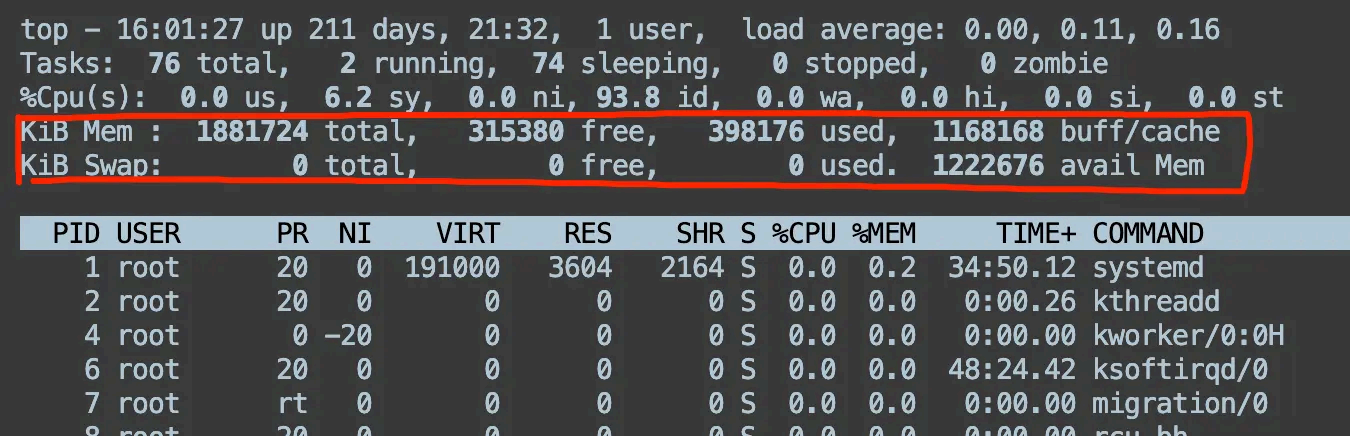
top 命令会 展示什么东 西,里面每一项都是呈现什么 样的数据?
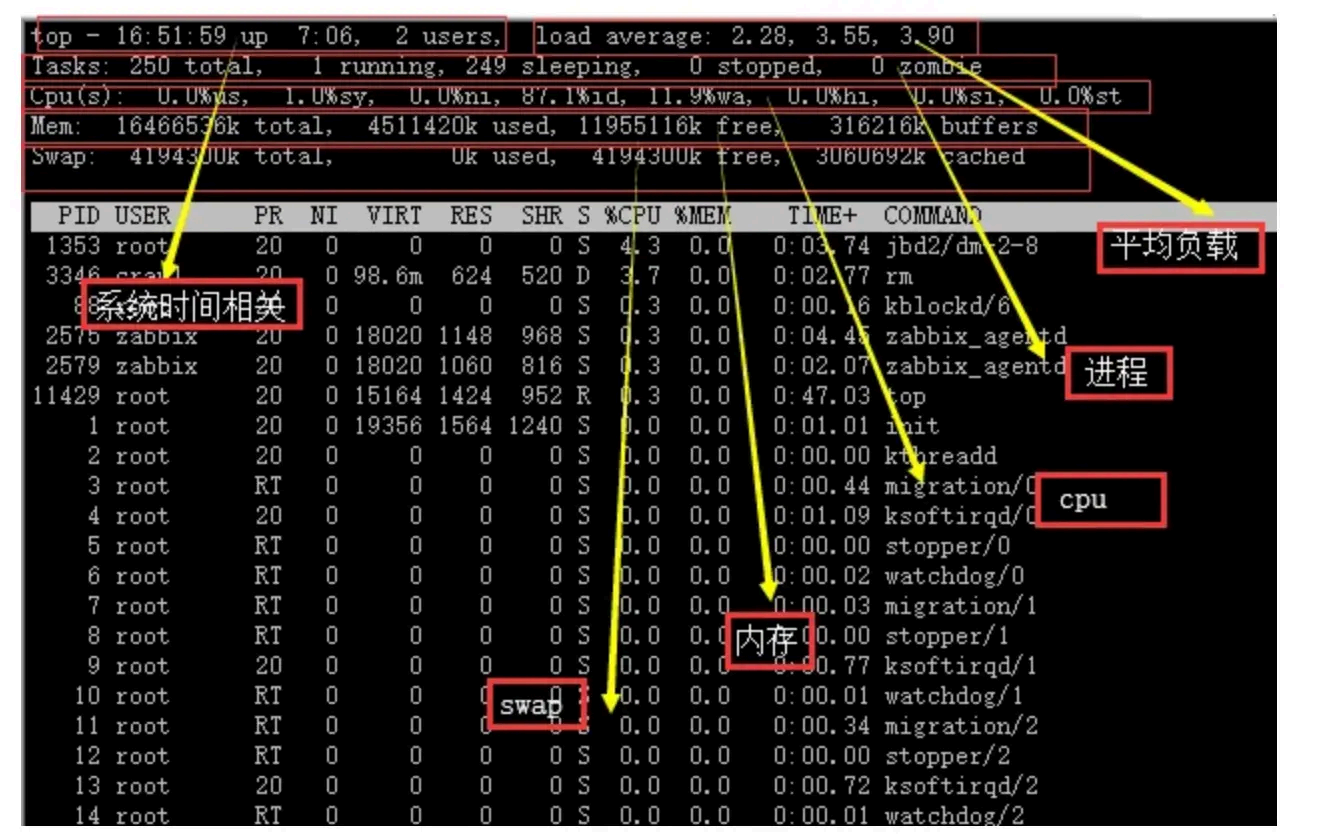
主要会展示:
Load average (平均负载):显示系统在最近1分钟、5分钟和15 分钟内的平均负载情况。
Tasks (任务):显示当前运行、睡眠 、停止和僵尸状态的进程数量。
CPU usage (CPU 使用情况):显示CPU 的总体使 用率以及每个CPU 核心的使用率。
Memory usage (内存使用情况):显示物理内存的总量、已使用量、空闲量、缓冲区和缓存区
的使用量。
Swap usage (交换空间使用情况):显示交换空间的总量、已使用量和剩余量。
进程列表:显示当前运行的进程列表,包括进程的PID 、用户、CPU 占用率、内存占用率、进程
状态、启动时间和进程命令。
已知一个进程名,如何杀掉这个进程?
在Linux 操作系统,可以使 用kill 命令来杀 死进程。
首先,使用ps 命令查找进程的PID (进程ID ),然后使用kill 命令加上PID 来终止进程。例如:
ps -ef | grep <进程名> // 查找进程的PID
kill <PID> // 终止进程linux 如何查看进程状态?
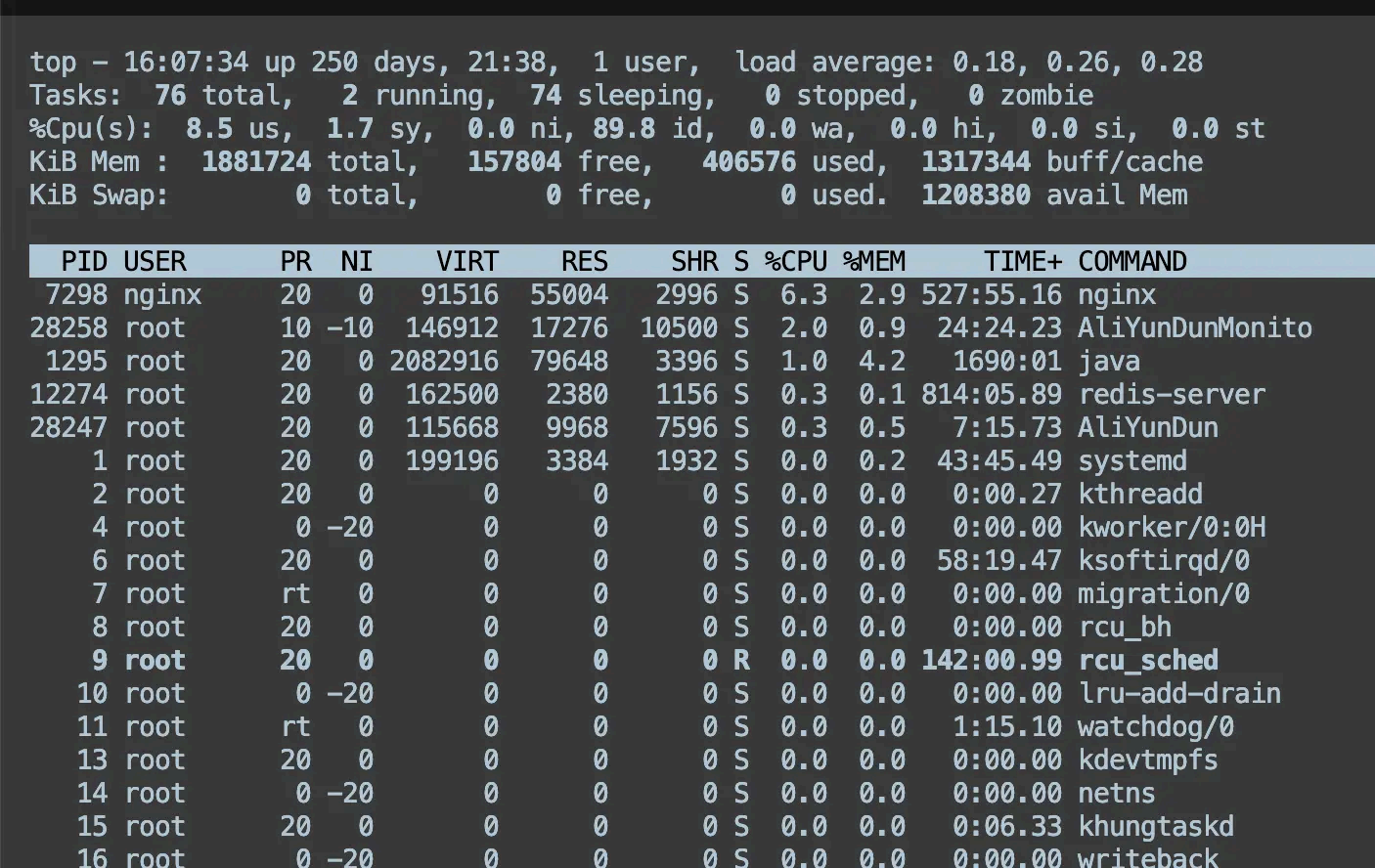
可以通过 ps 命令或者 top 命令来查 看进程的状态。
比如我想看 nginx 进程的状态,可以在 linux 输入这条命令:

top 命令除了能看进程的状态,还能看到系统的信息,比如系统负载、内存、cpu 使用率等等
linux 如何查看线程状态?
在 ps 和 top 命令加一下参数,就能看到线程状态了:
top -H
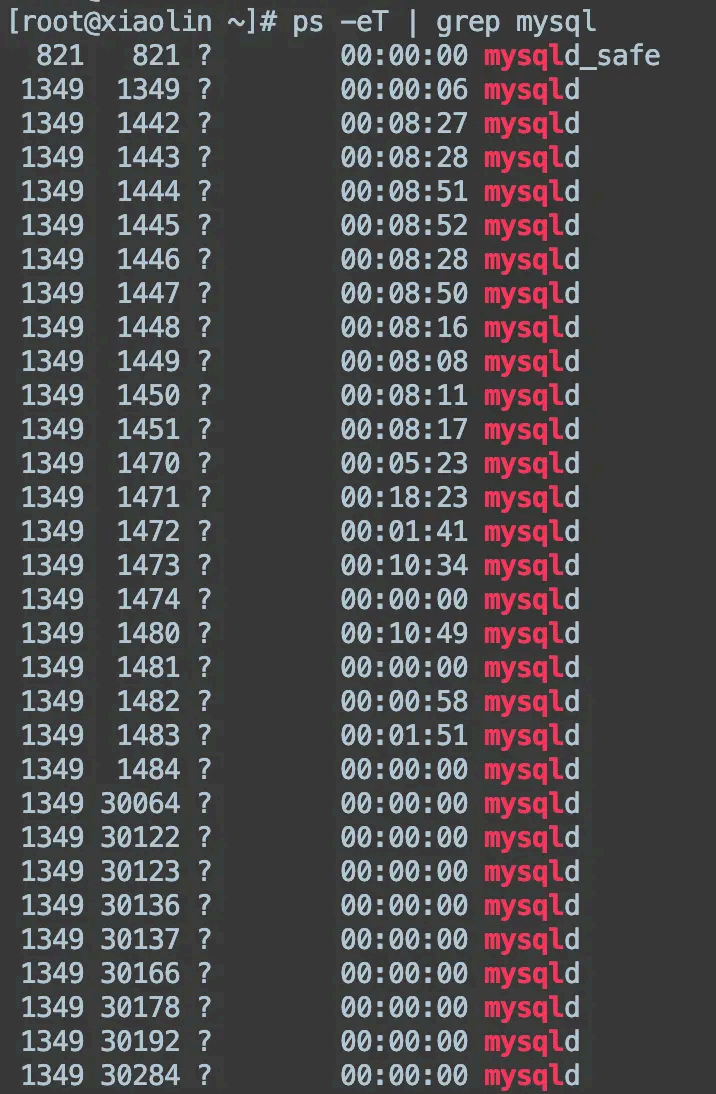
ps -eT | grep <进程名或线程名 >如何查看网络连接情况?
可以通过 netstat 命令来查 看网络连接的情况,比如下面,我通过 命令:
netstat -napt
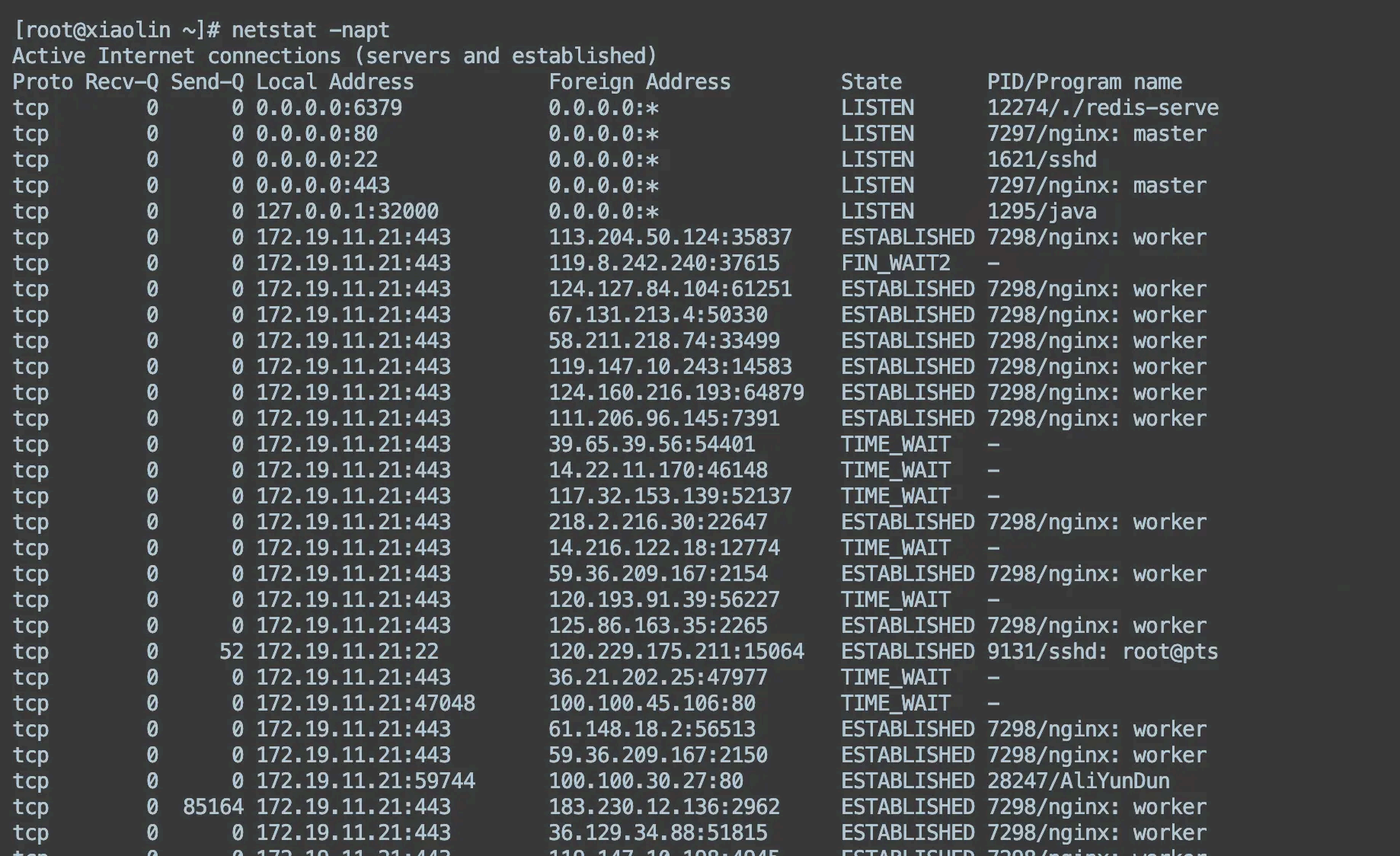
显示了服务器上的 tcp 连接状态,可以观察到每一个 tcp 连接的状态,以及四元组信息(源 ip 地址、目标 ip 地址 ,源端口、源 ip )
怎么查看哪个端口被哪个进程占用?
可以通过 lsof 或者 netstate 命令查看,比如查看 80 端口。
lsof :
netstat -napt
[root@xiaolin ~]# lsof -i :80COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 929 root 6u IPv4 15249 0t0 TCP *:http (LISTEN)
nginx 929 root 7u IPv6 15250 0t0 TCP *:http (LISTEN)
nginx 934 nginx 6u IPv4 15249 0t0 TCP *:http (LISTEN)
nginx 934 nginx 7u IPv6 15250 0t0 TCP *:http (LISTEN)AliYunDun 16507 root 10u IPv4 40212783 0t0 TCP xiaolin:41830->100.100.30.26:htt
netstate :
[root@xiaolin ~]# netstat -napt | grep 80tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 929/nginx: master p
端口通不通用什么 命令?
第一种方式:telnet :telnet 命令用于建立与远程主机的Telnet 连接,并可以使 用telnet 命令测试特
定端口的可访问性。
示例: telnet IP 地址 端口号 用于测试指定IP 地址 上的指定端口是否可 访问。如果能够建立连
接,则表示端口通畅;如果连接失败或超时,则表示端口不可访问。
第二种方式:nc :nc 命令(也称为netcat )是一个网络工具,可以用于创建各种类型的网络连接,
包括测试端口的可访问性。
示例: nc -zv IP 地址 端口号 用于测试指定IP 地址 上的指定端口是否可 访问。如果能够成功连
接,则表示端口通畅;如果连接失败或拒 绝,则表示端口不可访问。
top 命令查看是多少个 CPU 核心?
执行 top 命令之后,按数字 1,就能显示 CPU 有多少个核心了。

修改文件权限用什么 命令?
用 chmod 命令,可以修改文件或目录的权限。
以下是几个使用chmod 命令修改文件权限的例子:
将文件(例如file.txt )设置为只读权限:
chmod 400 file.txt
将文件设置为所有者可读写权限,其他用户只能读取权限:
chmod 644 file.txt
将文件设置为所有者可读写执行权限,所属组用户可读执行权限,其他用户只能读取权限:
chmod 755 file.txt
将目录设置为所有者可读写执行权限,所属组用户可读执行权限,其他用户只能读取权限:
chmod 755 directory/
在这些例子中,chmod 命令后面的三个 数字代表了不 同的权限组:
第一位表示所有者的权限。
第二位表示所属组的权限。
第三位表示其他用户的权限。
每个数字可以使 用 0-7 之间的数值来表示权限:
0 表示没有权 限。
1 表示执行权限。
2 表示写权限。
4 表示读权限。
可以根据需要自由组合这些数字来设置文件或目录的权限。
top 命令和 free 命令都可以查看内存,有什么 区别?
free 命令主要是查看系统的内存使用情况

物理内存:
total :总物理内存大小
used :已使用的内存
free :未使用的内存
shared :共享内存大小
buff/cache :缓冲和缓存内存大小
available :当前可用的内存,考虑到了部分缓存可以被快速释放的情况
交换内存:
total :总交换内存大小
used :已使用的交换内存
free :未使用的交换内存
top 命令,除了会显示系统内存情况,还会显示系统任务情况、CPU 使用情况、各进程状态等信
息。
用shell 命令替换一个文件中的字符串
可以使 用sed 命令。以下是一个示例:
sed -i 's/ 旧字符串 /新字符串 /g' 文件名
在上面的命令中,-i 选项表示直接在原始文件中进行修改,而不是输出到 标准输出。s/ 旧字符串/新
字符串/g 是替换操作的模式,其中旧字符串是要替换的字符串,新字符串是替换后的新字符串。g
表示全局替换,即一行中出现多次的旧字符串都会被替换。
请注意,这将直接修改原始文件,如果需要备份原始文件,可以在-i 选项后面指定一个备份文件的
扩展名,例如-i.bak ,这将在替换前备份原始文件。
例如,假设要将文件example.txt 中的字符串Hello 替换为Hi ,可以运行以下命令:
sed -i 's/Hello/Hi/g' example.txt
sed 和awk 有什么 区别?
都是用于文本处理命令的工具,区别在于:
sed ,主要用于对文本进行替换、删除、插入等操作。它适合对整行文本进行处理,可以通过正
则表达式匹配文本进行操作。
awk ,可以实现更复杂的文本处理逻辑,包括对字段的操作、条件判断、循环等。它适合处理结
构化的文本数据,可以按列对数据进行处理。
sed 适合简单的文本替 换和编辑操作,而awk 适合处理结构化的文本数据并实现更复杂的处理逻辑
查找日志中某个字符的长度?
要在 Linux 中查找日志文件中某个字符的长度,你可以使 用一些工具和命 令来实现。其中,grep
是一个强大的命令行工具,可以用于在文件中查找匹配指定模式的行。你也可以结合一些其他命
令来完成这个任务,如 awk 或者 sed 。
以下是一个示例命令,用于查找日志文件中某个字符的长度:
grep "search_string" log_file | awk '{ print length }在这个命令中:
1. grep "search_string" log_file 会找到日志文件中包含 "search_string" 的所有行。
2. awk '{ print length }' 会输出每一行的长度,即搜索到的 "search_string" 的长度。如果你想查找日志文件中单个字符的长度,你可以直接使用 grep 命令配合 wc 命令来实现:
sed -i 's/Hello/Hi/g' example.txt
grep "search_string" log_file | awk '{ print length }'这个命令会 计算搜索到的字符 "c" 在日志文件中出现的次数。
linux 中有一个日志文件,日志文件中记录了访问请求的信息,第一列是访问的日期,第二列是请求的ip,第三列是请求的耗时,写一条shell命令来查到请求耗时最高的10条记录
要查找请求耗时最高的10 条记录,可以使 用以下Shell 命令:
sort -k3 -nr 日志文件 | head -n 10
在上面的命令中,sort -k3 -nr 用于按第三列(请求耗时)进行倒序排序。-k3 表示按第三列排序,-n表示按数字排序,-r 表示倒序排序。然后,使用head -n 10 来获取排序后的前10 行,即耗时最高
的10 条记录。
将命令中的“日志文件”替换为实际的日志文件路径,即可查找到请求耗时最高的10 条记录。
假如cpu 跑到100% ,你的解决思路是什么 ?
思路如下:
先通过 top 命令,定位到占用 cpu 高的进程
然后通过 ps -T -p<> < 进程ID> 命令找到进程中占用比较高的线程然后通过 jstack 命令去查看该线程的堆栈信息
根据输出的堆栈信息,去项目中定位代 码,看是否发生了死循环而导致cpu 跑到100%
Linux 服务器当中如何查看负载情况?通过什么 指标进行查看?
通常我们发现系统变慢时,我们都会执行top 或者uptime 命令,来查 看当前系统的负载情况,比如
像下面,我执 行了uptime ,系统返回的了结果,最后一个就是系统平均负载的情况。

Load Average 的三个 数字,依次则是过去1分钟、5分钟、15 分钟的平均负载。可以通过观察这三个数字的大小,可以简单判断系统的负载是下降的趋势还是上升的趋势。负载值一般不超过cpu 核
数的1-1.5 倍,如果超过1.5 倍,那就要重视,此时会严重影响系统。
如果 load average: 1.00, 5.00, 10.00 三个 数字依次增大,则说明在过去的 1 分钟系统的负载比
过去 15 分钟系统的负载小,表明系统的负载是下降的趋势。
如果 load average: 10.00, 5.00, 1.00 三个 数字依次降低,则说明在过去的 1 分钟系统的负载比
过去 15 分钟系统的负载大,表明系统的负载是上升的趋势。
如果 load average: 0.07, 0.04, 0.0 三个 数字基本相同,或者相差不大, 表明系统的负载是平稳
的。
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅 包括了正在
使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完 全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
我们现在很清楚的知道导致平均负载高的情况,不只是看 CPU 的使用率,也要观 察系统 I/O 等待
时间高不高。
当发现平均负载升高时,可以使 用 mpstat 命令查看 CPU 的性能。
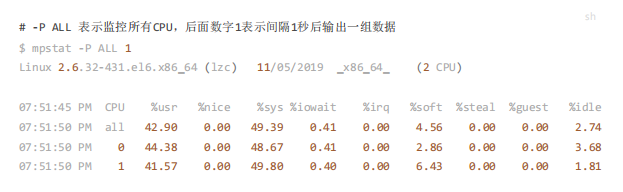
从上 面发现
CPU 的用户层(%usr )使用率高达45% 左右;
CPU 的系统层(%sys )使用率高达50% 左右;
CPU 的 I/0 - 等待(%iowait )占用率为0.41% ;
CPU 的空闲率(%idle )只有2~3% 。
-P ALL 表示监控所有 CPU ,后面数字 1表示间隔 1秒后输出一组数据
可以推断出是由于 CPU 使用率导致平均负载升高的情况。
假设只有 CPU 的I/0 等待(%iowait )占用率高,CPU 用户层和系统层使用率很轻松,那么导致平
均负载升高的原因就是 iowait 的升高。
判断了是因为 CPU 使用率升高还是 iowait 升高导致平均负载升高后,我们还需要定位是哪个进程
导致的。可以用 pidstat 来查 询:
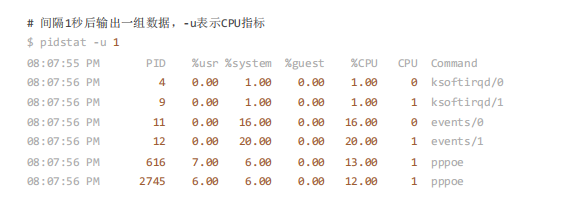
可以发现是 events/0 和 events/1 内核进程 CPU 使用率非常高,所以可能这两个 进程导致平均负
载升高。
怎么判断服务器内存是否够用?如何查看服务器性能瓶颈是否是内存?
使用 free 命令查看内存使用情况
使用 free -m 命令可以查看内存的总体使 用情况,输出结果会大致如下:

关注以下几项:
used :已经使用的内存。
free :可用的空闲内存。
available :可用的内存,这包括了操作系统缓存,这个值更能代表实际可用内存。
如果 available 的值长期很低,可能表明内存不足。
间隔 1秒后输出一组数据, -u 表示 CPU 指标
通过观察是否频繁使用 Swap 空间
可以通过 free 命令观察 Swap 空间的使用情况:

如果 Swap 空间使用过多(例如,接近 Swap total ),说明物理内存不足。
检查 dmesg 输出是否有 OOM (Out of Memory )信息
查看 /var/log/messages 或者使用 dmesg 命令来查 看系统日志,检查是否有 OOM (Out of Memory )错误。
dmesg | grep -i "out of memory
如果存在 OOM 错误,说明内存不足是一个明显 的问题。
使用 vmstat 观测内存使用状况
vmstat 是另一个强大的工具,可以帮助你监控系统的内存使用情况。执行 vmstat 1 每秒刷新一
次:

特别关注以下字段:
si (swap in )和 so (swap out ):如果这两个 值较高,说明系统频繁使用交换空间,表明物理
内存可能不足。
free :空闲内存。
buff 和 cache :缓存和缓冲区的使用情况。
如何判断内存是否是满的情况?通过什么 指标判断内存的使用率?
如果 free 和 available 都非常低,而 used 很高,内存基本上是满的。
Swap 使用频繁且使用率较高,那么内存基本上是满的。
如果 dmesg 日志,出现 OOM 相关信息,说明内存不足导致了一些进程被杀掉。
ps 或 top 显示大部分内存被少数几个进程占用,那么内存基本上是满的。
怎么判断操作系统有没有在内存替换?或者说怎么统计内存替换的频率?
我们可以使 用 sar -B 1 命令来观察:

图中红色框住的就是后台 内存回收和直接内存回收的指标,它们分别 表示:
pgscank/s : kswapd( 后台 回收线程) 每秒扫描的 page 个数。pgscand/s: 应用程序在内存申请过程中每秒直接扫描的 page 个数。
pgsteal/s: 扫描的 page 中每秒被回收的个数(pgscank+pgscand )。
如果系统时不时发生抖动,并且在抖动的时间段里如果通过 sar -B 观察到 pgscand 数值很大,那
大概率是因为「直接内存回收」导致的。