
场景
携程 Java ⾯试
昨天公布了互联⽹公司 25 届校招薪资 ,底部有读者留⾔想看看 携程的薪资和⾯经。
之前有同学刚参加完携程的线下⾯试,流程是⼀⼆⾯+HR ⾯,当天下午就直接速通 了,速通 之后
就等后⾯的 offer 录取通知了,如果是线上⾯试的话,有时候流程会需要⾛ 2-3 周,整体还是⽐较
慢,最快也需要⼀周,所以线下⾯试效率还是⾮常快的,快⼈⼀步拿 offer 。
25 届携程开发岗位的校招薪资如下:

整体看,携程的年薪是有 30-40w 的,薪资待遇还是不错的,跟⼀线⼤⼚差不多了,训练营也有同
学拿到了携程 offer ,薪资开了 sp offer ,还算满意,最后选择去携程。
那携程⾯试到底难度如何呢?
那么,这次来分享⼀位同学携程的Java 后端开发的⾯经,主要是考察了Java 集合、Java IO 、Java
并发、SSM 、场景题、系统设计 ⽅⾯的知识。⼀般来说,携程⾯试还是会出算法的,不过这 个同
学当时是 没有⼿撕算法,⾯试时⻓⼤概 40 分钟。

Java
Java 中常⽤集合有哪些?

List 是有序的Collection ,使⽤此接⼝能够精确的控制每个元素的插⼊位置,⽤⼾能根据索引访问
List 中元素。常⽤的实现List 的类有LinkedList ,ArrayList ,Vector ,Stack 。
ArrayList 是容量可变的⾮线程安全列表,其底层使⽤数组实现。当发⽣扩容时,会创建更⼤的
数组,并把原数组复制到 新数 组。ArrayList ⽀持对元素的快速随机访问,但插⼊与删除速度很
慢。
LinkedList 本质是⼀个双向链表,与ArrayList 相⽐,,其插⼊和删除速度更快,但随机访问速度更
慢。
Vector 与 ArrayList 类似,底层也是基于数组实现,特点是线程安全,但效率相对较低,因为其
⽅法⼤多被 synchronized 修饰
Map 是⼀个键值对集合,存储键、值和之间的映射。Key ⽆序,唯⼀;value 不要求有序,允许重
复。Map 没有继承于 Collection 接⼝,从 Map 集合中检索元素时,只要给出键对象,就会返回对
应的值对象。主要实现有TreeMap 、HashMap 、HashTable 、LinkedHashMap 、
ConcurrentHashMap
HashMap :JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主
要为了 解决哈希冲突⽽存在的(“拉链法”解决冲 突),JDK1.8 以后在解决哈希冲突时有了较⼤的
变化 ,当链表⻓度⼤于阈值(默认为 8)时,将链表转化为红⿊树,以减少搜索时间
LinkedHashMap :LinkedHashMap 继承⾃ HashMap ,所以它的底层仍然是基于拉链式散列结
构即由数组和链表或红⿊树组成。另外,LinkedHashMap 在上⾯结构的基础上,增加了⼀条双
向链表,使得上⾯的结构可以保 持键值对的插⼊顺序。同时通过对链表进⾏相应的操作,实现
了访问顺序相关逻辑。
HashTable :数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了 解决哈希冲突⽽
存在的
TreeMap :红⿊树(⾃平衡的排序⼆叉树)
ConcurrentHashMap :Node 数组+链表+红⿊树实现,线程安全的(jdk1.8 以前Segment 锁,
1.8 以后volatile + CAS 或者 synchronized )
Set 不允许存在重复的元素,与List 不同,set 中的元素是⽆序的。常⽤的实现有HashSet ,
LinkedHashSet 和TreeSet 。
HashSet 通过HashMap 实现,HashMap 的Key 即HashSet 存储的元素,所有Key 都是⽤相同的
Value ,⼀个名为PRESENT 的Object 类型常量。使⽤Key 保证元素唯⼀性,但不保证有序性。由
于HashSet 是HashMap 实现的,因此线程不安全。
LinkedHashSet 继承⾃HashSet ,通过LinkedHashMap 实现,使⽤双向链表维护元素插⼊顺序。
TreeSet 通过TreeMap 实现的,添加元素到集合时按照⽐较规则将其插⼊合适的位置,保证插⼊
后的集合仍然有序。
HashMap 的实现原理?
在 JDK 1.7 版本之前, HashMap 数据结构是数组和链表,HashMap 通过哈希算法将元素的键
(Key )映射到数组中的槽位(Bucket )。如果多个键映射到同⼀个槽位,它们会以 链表的形式 存
储在同⼀个槽位上,因为链表的查询时间是O(n) ,所以冲突很严重,⼀个索引上的链表⾮常⻓,效率就很低了。

所以在 JDK 1.8 版本的时候做 了优化,当⼀个链表的⻓度超过8的时候就转换数据结构,不再使⽤
链表存储,⽽是使⽤红⿊树,查找时使⽤红⿊树,时间复杂度O(log n ),可以提⾼查询性能,但
是在数量较少时,即数量⼩于6时,会将红⿊树转换回链表。

HashSet 的实现原理及使⽤原理?
HashSet 实现原理:
数据结构实现原理:HashSet 是基于哈希表实现的,HashSet 内部使⽤⼀个 HashMap 来存储元
素。实际上,HashSet 可以看作是对 HashMap 的简单封装,它只使⽤了 HashMap 的键(Key )
来存储元素,⽽值(Value )部分被忽略(在 Java 的 HashMap 实现中,所有 HashSet 中的元素
对应的 Value 是⼀个固定的 Object 对象,通常是⼀个名为 PRESENT 的静态常量)。
元素存储过程:当向 HashSet 中添加⼀个元素时,⾸先会计算该元素的哈希码,然后通过哈希
函数得到桶的索引。接着检查该桶中是否已经存在元素。如果桶为空,则直接将元素插⼊到该
桶中;如果桶不为 空,则遍历桶中的链表(或红⿊树),⽐较元素的哈希码和 equals ⽅法(在
Java 中,判断两个 元素是否相等,先⽐较哈希码是否相同,若相同再⽐较 equals ⽅法是否返回
true )。如果没有找到相同的元素(即哈希码和 equals ⽅法都不匹配),则将元素添加到 链表
(或红⿊树)中;如果找到相同的元素,则认为该元素已经存在于 HashSet 中,不会重复添
加。
元素查找过程:查找⼀个元素是否在 HashSet 中也 是类似的过程。先计算元素的哈希码,然后
通过哈希函数得到桶的索引。接着在对应的桶中查找元素,通过⽐较哈希码和 equals ⽅法来判
断元素是否存在。由于哈希函数能够快速定位到元素可能存在的桶,所以在理想情况下,
HashSet 的查找操作时间复杂度可以接近常数时间 O (1) ,但在最坏情况下(所有元素都哈希到
同⼀个桶),时间复杂度会退化为 O (n) ,其中 n 是 HashSet 中的元素个数。HashSet 使⽤原理:
添加元素:使⽤ add ⽅法可以将元素添加到 HashSet 中。例如,在 Java 中, HashSet<String>
> set = new HashSet<>(); set.add("example");就将 字符串 “example” 添加到 了 HashSet 中。
检查元素是否存在:使⽤ contains ⽅法来检查⼀个元素是否存在于 HashSet 中。例如,
> set.contains("example")会返回 true ,因为刚刚 添加了这个元素。
删除元素:通过 remove ⽅法删除元素。如 set.remove("example"); 会将刚刚 添加的元素从HashSet 中删除。
ArrayList 和 LinkedList 有什么 区别?
ArrayList 和LinkedList 都是Java 中常⻅的集合类,它们都实现了List 接⼝。
底层数据结构不同:ArrayList 使⽤数组实现,通过索引进⾏快速访问元素。LinkedList 使⽤链表
实现,通过节点之间的指针进⾏元素的访问和操作。
插⼊和删除操作的效率不同:ArrayList 在尾部的插⼊和删除操作效率较⾼,但在中间或开头的
插⼊和删除操作效率较低,需要移动元素。LinkedList 在任意位置的插⼊和删除操作效率都⽐较
⾼,因为只需要调整节点之间的指针。
随机访问的效率不同:ArrayList ⽀持通过索引进⾏快速随机访问,时间复杂度为O(1) 。
LinkedList 需要从头或尾开始遍历链表,时间复杂度为O(n) 。空间占⽤:ArrayList 在创建时需要分配⼀段连续的内存空间,因此会占⽤较⼤的空间。
LinkedList 每个节点只需要存储元素和指针,因此相对较⼩。
使⽤场景:ArrayList 适⽤于频繁随机访问和尾部的插⼊删除操作,⽽LinkedList 适⽤于频繁的中
间插⼊删除操作和不需要随机访问的场景。
线程安全:这两个 集合都不是线程安全的,Vector 是线程安全的
双亲委派策略是什么 ?
双亲委派模型是 Java 类加载器的⼀种层次化加载策略。在这种策略下,当⼀个类加载器收到类加
载请求时,它⾸先不会⾃⼰去尝试加载这 个类,⽽是把这个请求委派给它的⽗类加载器。只有当
⽗类加载器⽆法完成加载任务时,才由⾃⼰来加载。
在 Java 中,类加载器主要有以下⼏种,并且存在层次关系。
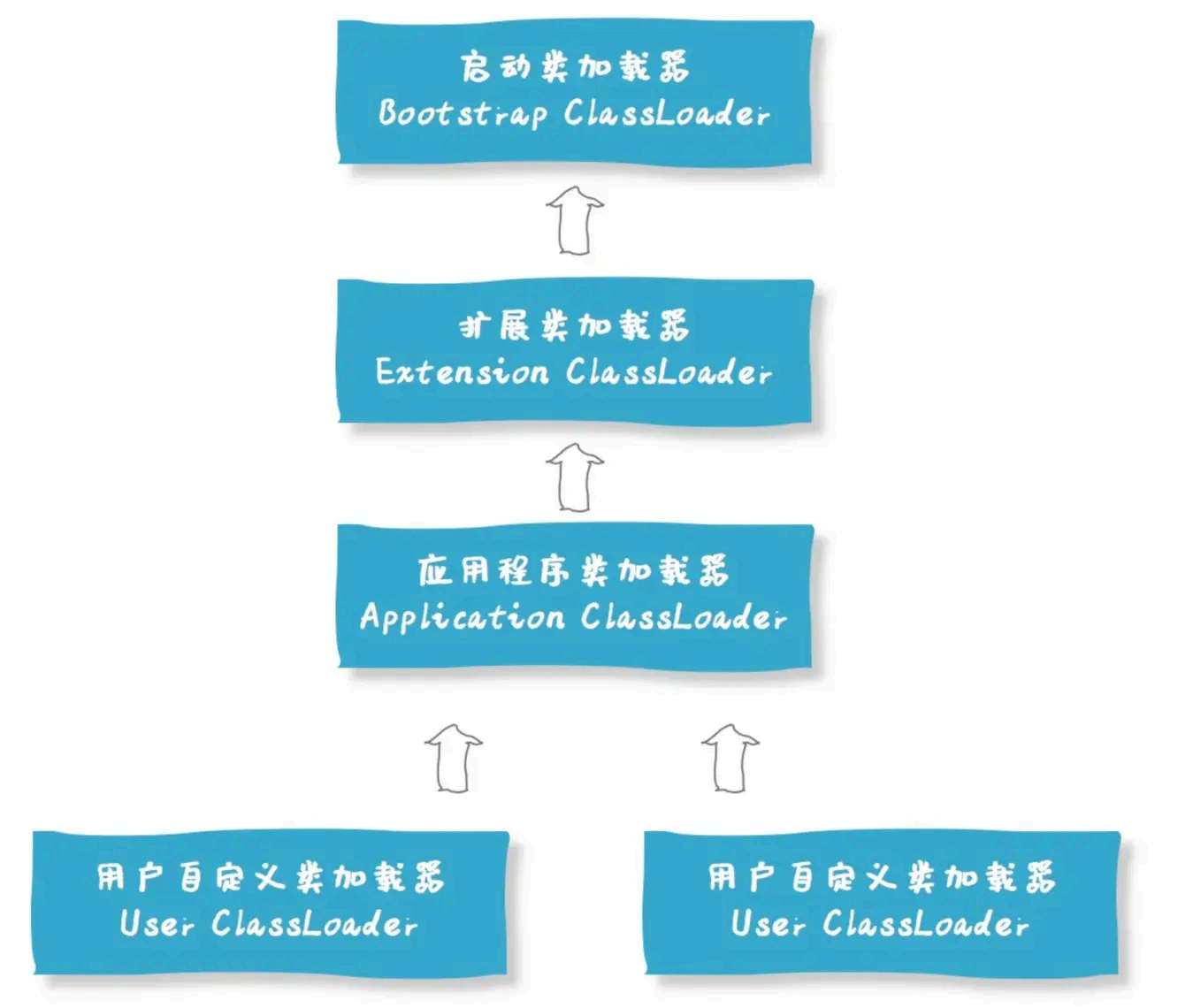
启动类加载器( Bootstrap ClassLoader ):它是最顶层的类加载器, 主要负责 加载 Java 的核⼼
类库,例如存放在 <JAVA_HOME>/lib ⽬录下的 rt.jar 等核⼼库。它是由 C++ 编写的,是虚拟机的⼀部分,没有对应的 Java 类,在 Java 代码中⽆法直接引⽤它。
扩展类加载器( Extension ClassLoader ):它的⽗加载器是启动类加载器。主要负责 加载
<JAVA_HOME>/lib/ext ⽬录下的类库或者由 java.ext.dirs 系统属性指定路径中的类库。它是由 Java 编写的,对应的 Java 类是 sun.misc.Launcher$ExtClassLoader 。
应⽤程序类加载器( Application ClassLoader ):也称为系统类加载器, 它的⽗加载器是扩展类
加载器。主要负责 加载⽤⼾类路径( classpath )上的类库,这是我们在⽇常编程中最常接触
到的类加载器, 对应的 Java 类是 sun.misc.Launcher$AppClassLoader 。⾃定义类加载器( Custom Class Loader ):开发者可以根据需求定制类的加载⽅式,⽐如从⽹
络加载class ⽂件、数据库、甚⾄是加密的⽂件中加载类等。⾃定义类加载器可以⽤来扩展Java应⽤程序的灵活性和安全性,是Java 动态性 的⼀个重要体现。
当⼀个类加载请求到达应⽤程序类加载器时,它会先把请求委派给它的⽗加载器( 扩展类加载
器) 。扩展类加载器收到请求后,也会先委派给它的⽗加载器( 启动类加载器) 。启动类加载器会
尝试从⾃⼰负责 的核⼼类库中加载这 个类,如果能加载成功,就返回加载的类;如果不能加载,
就把请求返回给扩展类加载器。扩展类加载器再尝试从⾃⼰负责 的扩展类库中加载,如果成功就
返回,否则将请求返回给应⽤程序类加载器。最后,应⽤程序类加载器从⾃⼰负责 的类路径中加
载这 个类。
双亲委派模型优势是:
安全性:通过双亲委派策略,保证了 Java 核⼼类库的安全性。例如, java.lang.Object 这个
类是由启动类加载器加载的。如果没有这种策略,⽤⼾可能会编写⼀个⾃⼰的
java.lang.Object 类,并且通过⾃定义的类加载器加载,这会导致整个 Java 类型系统的混
乱。⽽双亲委派策略使得像 java.lang.Object 这样的核⼼类始终由启动类加载器加载,防⽌了
⽤⼾代码对核⼼类库的恶意篡改。
避免类的重复加载:由于类加载请求是由上到下进⾏委派的,当⼀个类已经被⽗类加载器加载
后,⼦类加载器就不会再重复加载。例如,某个类在扩展类库中已经被加载,那么应⽤程序类
加载器就不会再次加载这 个类,从⽽提⾼了加载效率,节省了内存空间。
深拷⻉和浅拷⻉的区别?怎么实现?

浅拷⻉是指只复制对象本⾝和其内 部的值类型字段,但不会复制对象内部的引⽤类型字段。换
句话说,浅拷⻉只是创建⼀个新的对象,然后将原对象的字段值复制到 新对象中,但如果原对
象内部有引⽤类型的字段,只是将引⽤复制到 新对象中,两个 对象指向的是同⼀个引⽤对象。
深拷⻉是指在复制对象的同时,将对 象内部的所有引⽤类型字段的内容也复制⼀份,⽽不是共
享引⽤。换句话说,深拷⻉会递归复制对象内部所有引⽤类型的字段,⽣成⼀个全新的对象以
及其内 部的所有对象。
序列化和反序列化实现的是深拷⻉还是浅拷⻉?
Java 创建线程的⽅式有哪些?
- 继承Thread 类
这是最直接的⼀种⽅式,⽤⼾⾃定义类继承java.lang.Thread 类,重写其 run() ⽅法,run() ⽅法中定义了 线程执⾏的具体任 务。创建该类的实例后,通过调⽤start() ⽅法启动线程。
class MyThread extends Thread {
@Override
public void run () {
}
public static void main(String[] args) {
MyThread t = new MyThread();
t.start();
}采⽤继承Thread 类⽅式
优点: 编写简单,如果需要访问当前线程,⽆需使⽤Thread.currentThread () ⽅法,直接使⽤this ,即可获得当 前线程
缺点:因为线程类已经继 承了Thread 类,所以不能再继承其他的⽗类
** 2. 实现Runnable 接⼝**
如果⼀个类已经继 承了其他类,就不能再继承Thread 类,此时可以实现java.lang.Runnable 接⼝。
实现Runnable 接⼝需要重写run() ⽅法,然后将此Runnable 对象作为参数传递给Thread 类的构造
器, 创建Thread 对象后调⽤其start() ⽅法启动线程。
class MyRunnable implements Runnable {
@Override
public void run() {
// 线程执行的代码
}
}
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start();
}采⽤实现Runnable 接⼝⽅式:
优点:线程类只是实现了Runable 接⼝,还可以继承其他的类。在这种⽅式下,可以多个线程共
享同⼀个⽬标对象,所以⾮常适合多个相同线程来处理同⼀份资源的情况,从⽽可以将CPU 代
码和数据分开,形成清晰的模型,较好地体现了⾯向对象的思想。
缺点:编程稍 微复杂,如果需要访问当前线程,必须使⽤Thread.currentThread() ⽅法。- 实现Callable 接⼝与FutureTask
java.util.concurrent.Callable 接⼝类似于Runnable ,但Callable 的call() ⽅法可以有返回值并且可以抛出异常。要执⾏Callable 任务,需将它包装进⼀个FutureTask ,因为Thread 类的构造器只接
受Runnable 参数,⽽FutureTask 实现了Runnable 接⼝。
class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
// 线程执行的代码,这里返回一个整型结果
return 1;
}
}
public static void main(String[] args) {
MyCallable task = new MyCallable();
FutureTask<Integer> futureTask = new FutureTask<>(task);
Thread t = new Thread(futureTask);
t.start();
try {
Integer result = futureTask.get(); // 获取线程执行结果
System.out.println("Result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}采⽤实现Callable 接⼝⽅式:
缺点:编程稍 微复杂,如果需要访问当前线程,必须调⽤ Thread.currentThread() ⽅法。优点:线程只是实现Runnable 或实现Callable 接⼝,还可以继承其他类。这种⽅式下,多个线程
可以共享⼀个target 对象,⾮常适合多线程处理同⼀份资源的情形。
- 使⽤线程池(Executor 框架)
从Java 5 开始引⼊的 java.util.concurrent.ExecutorService 和相关类提供了线程池的⽀持,这是
⼀种更⾼效的线程管理⽅式,避免了频繁创建和销毁线程的开销。可以通过Executors 类的静态⽅
法创建不同类型的线程池。
class Task implements Runnable {
@Override
public void run() {
// 线程执行的代码
}
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10); // 创建固定大小的线程池
for (int i = 0; i < 100; i++) {
executor.submit(new Task()); // 提交任务到线程池执行
}
executor.shutdown(); // 关闭线程池
}采⽤线程池⽅式:
缺点:程池增加了程序的复杂度,特别是当涉及线程池参数调整和故障排查时。错误的配置可
能导致死锁、资源耗尽等问题,这些问题的诊断和修复可能较为复杂。
优点:线程池可以重⽤预先创建的线程,避免了线程创建和销毁的开销,显著提⾼了程序的性
能。对于需要快速响应的并发请求,线程池可以迅速提供线程来处理任务,减少等待时间。并
且,线程池能够有效控制运⾏的线程数量,防⽌因创建过多线程导致的系统资源耗尽(如内存
溢出)。通过合理配置线程池⼤⼩,可以最⼤化CPU 利⽤率和系统吞吐 量。
线程池使⽤的时候应该注意哪些问题?
线程池是为了 减少频繁的创建线程和销毁线程带来的性能损耗,线程池的⼯作原理如下图:

线程池分为核⼼线程池,线程池的最⼤容量,还有等待任务的队列,提交⼀个任务,如果核⼼线
程没有满,就创建⼀个线程,如果满了,就是会加⼊等待队列,如果等待队列满了,就会增加线
程,如果达到最⼤线程数量,如果都达到最⼤线程数量,就会按照⼀些丢 弃的策略进⾏处理。
线程池使⽤的时候应该注意以下问题。
- 线程池⼤⼩的合理设置性
核⼼线程数(Core Pool Size ):核⼼线程数是线程池在没有任务时保持的线程数量。如果设置
得太⼩,当有⼤量任务突然到达时,线程池可能⽆法及时处理,导致任务在队列中等待时间过
⻓。例如,对于⼀个 CPU 密集型的任务,核⼼线程数⼀般可以设置为 CPU 核⼼数加 1,这样可
以充分利 ⽤ CPU 资源,同时避免过多的上下 ⽂切换。如果是 I/O 密集型任务,由于线程⼤部分
时间在等待 I/O 操作完成,核⼼线程数可以设置得相对⼤⼀些,通常可以根据 I/O 设备的性能
和任务的 I/O 等待时间来估算,⽐如可以设置为 CPU 核⼼数的两倍。
最⼤线程数(Maximum Pool Size ):最⼤线程数决定了线程池能够同时处理任务的上限。如果
设置得过⼤,可能会导致系统资源耗尽,如内存不⾜或者 CPU 过度切换上下 ⽂⽽导致性能下
降。设置最⼤线程数时需要考虑系统的资源限制,包括 CPU 、内存等。并且,最⼤线程数与任
务队列的⼤⼩也有关系,当任务队列满了之 后,线程池会创建新的线程,直到达到最⼤线程
数。
阻塞队列(Blocking Queue )容量:阻塞队列⽤于存储等待执⾏的任务。如果队列容量设置得
过⼩,可能⽆法容纳⾜够的任务,导致任务被拒绝;⽽如果设置得过⼤,可能会导致任务在队
列中等待时间过⻓,增加响应时间。对于有优先级的任务队列,还需要考虑如何合理地设置优
先级,以确保⾼优先级的任务能够及时得到处理。
- 线程池的⽣命周 期管理
正确的启动和关闭顺序:要确保线程池在正确的时机启动和关闭。在启动线程池后,才能提交
任务给它执⾏;在系统关闭或者不再需要线程池时,需要正确地关闭线程池。关闭线程池可以使⽤ shutdown 或者 shutdownNow ⽅法。 shutdown ⽅法会等待正在执⾏的任务完成后再关 闭线
程池,⽽ shutdownNow ⽅法会尝试中断正在执⾏的任务,并⽴即关闭线程池,返回尚未执⾏的
任务列 表。
避免重复提交任务:在某些情况下,可能会出现重复提交任务的情况。⽐如在⽹络不稳定的情
况下,客⼾端可能会多次发送相同的请求,导致任务被多次提交到线程池。这可能会导致任务
的重复执⾏或者资源的浪费。可以通过在任务提交端进⾏去重处理,或者在任务本⾝的逻辑中
设置标志位来判断任务是否已经在执⾏,避免重复执⾏。
- 线程安全性和资源管理
共享资源访问控制:线程池中的线程会并发地执⾏任务,如果任务涉及到共享资源的访问,如
共享变量、数据库连接等,需要采取适当的同步措施,如使⽤ synchronized 关键字或者
ReentrantLock
等锁机制,以避免数据不⼀致或者资源竞争的问题。
资源的释放和清理:线程执⾏任务可能会占⽤各种资源,如⽂件句柄、⽹络连接等。在任务执
⾏完成后,需要确保这些资源得到正确的释放和清理,避免资源泄漏。可以在任务的 run ⽅法
或者 call ⽅法的最后进⾏资源的清理⼯作,如关闭⽂件流、释放数 据库连接等。
BIO 、NIO 、AIO 区别是什么 ?
BIO (blocking IO ):就是传统的 java.io 包,它是基于流模型实现的,交互 的⽅式是同步、阻塞
⽅式,也就是说在读⼊输⼊流或者输出流时,在读写动作完成之前,线程会⼀直阻塞在那⾥,
它们之间的调⽤是可靠的线性顺序。优点是代码⽐较简单、直观;缺点是 IO 的效率和扩展性很
低,容易成为应⽤性能瓶颈。
NIO (non-blocking IO ) :Java 1.4 引⼊的 java.nio 包,提供了 Channel 、Selector 、Buffer 等
新的抽象,可以构建多路复⽤的、同步⾮阻塞 IO 程序,同时提供了更接近操作系统底层⾼性能
的数据操作⽅式。
AIO (Asynchronous IO ) :是 Java 1.7 之后引⼊的包,是 NIO 的升级版本,提供了异步⾮堵
塞的 IO 操作⽅式,所以⼈们叫它 AIO (Asynchronous IO ),异步 IO 是基于事 件和回调机制实
现的,也就是应⽤操作之后会直接返回,不会堵塞在那⾥,当后台 处理完成,操作系统会通知相应的线程进⾏后续的操作。
三级缓存解决循环依赖⽅式是?
环依赖指的是两个 类中的属性相互依赖对⽅:例如 A 类中有 B 属性,B 类中有 A属性,从⽽形成
了⼀个依赖闭环,如下图。

循环依赖问题在Spring 中主 要有三种情况:
第⼀种:通过构造⽅法进⾏依赖注⼊时产⽣的循环依赖问题。
第⼆种:通过setter ⽅法进⾏依赖注⼊且是在多例(原型)模式下产 ⽣的循环依赖问题。
第三种:通过setter ⽅法进⾏依赖注⼊且是在单例模式下产 ⽣的循环依赖问题。
只有【第三种⽅式】的循环依赖问题被 Spring 解决了,其他两 种⽅式在遇到循环依赖问题时,
Spring 都会产⽣异常。
Spring 在 DefaultSingletonBeanRegistry 类中维护了三个 重要的缓存 (Map) ,称为“三级缓存”:
singletonObjects (⼀级缓存):存放的是完全初始化好的、可⽤的 Bean 实例, getBean() ⽅法最终返回的就是这⾥⾯的 Bean 。此时 Bean 已实例化、属性已填充、初始化⽅法已执⾏、
AOP 代理(如果需要)也已⽣成。
earlySingletonObjects (⼆级缓存):存放的是提前暴露的 Bean 的原始对象引⽤ 或 早期代理对象引⽤,专⻔⽤来处理循环依赖。当⼀个 Bean 还在创建过程中(尚未完成属性填充和初始
化),但它的引⽤需要被注⼊到另⼀个 Bean 时,就暂时 放在这⾥。此时 Bean 已实例化(调⽤
了构造函数),但属性尚未填充,初始化⽅法尚未执⾏,它可能是⼀个原始对象,也可能是⼀个为了 解决 AOP 代理问题⽽提前⽣成的代理对象。
singletonFactories (三级缓存):存放的是 Bean 的 ObjectFactory ⼯⼚对象。,这是解决循环依赖和 AOP 代理协同⼯作的关键。当 Bean 被实例化后(刚调完构造函数),Spring 会创建
⼀个 ObjectFactory 并将其放⼊三级缓存。这个⼯⼚的 getObject() ⽅法负责 返回该 Bean的早期引⽤(可能是原始对象,也可能是提前⽣成的代理对象),当检测到循环依赖需要注⼊⼀
个尚未完全初始化的 Bean 时,就会调⽤这个⼯⼚来获取早期引⽤。
Spring 通过 三级缓存 和 提前暴露未完全初始化的对象引⽤ 的机制来解决单例作 ⽤域 Bean 的
sette 注⼊⽅式的循环依赖问题。
假设存在两个 相互依赖的单例Bean : BeanA 依赖 BeanB ,同时 BeanB 也依赖 BeanA 。当
Spring 容器启动时,它会按照以下流程处理:
第⼀步:创建 BeanA 的实例并提前暴露⼯⼚。
Spring ⾸先调⽤ BeanA 的构造函数进⾏实例化,此时得到⼀个原始对象(尚未填充属性)。紧接
着,Spring 会将⼀个特殊的 ObjectFactory ⼯⼚对象存⼊第三级缓存( singletonFactories )。这
个⼯⼚的使命是:当其他Bean 需要引⽤ BeanA 时,它能动态返回当前这个半成品的 BeanA (可能是原始对象,也可能是为应对AOP ⽽提前⽣成的代理对象)。此时 BeanA 的状态是"已实例化但未初始化",像⼀座刚搭好钢筋⻣架的⼤楼。
第⼆步:填充 BeanA 的属性时触发 BeanB 的创建。
Spring 开始为 BeanA 注⼊属性,发现它依赖 BeanB 。于是容器转向创建 BeanB ,同样先调⽤其构造函数实例化,并将 BeanB 对应的 ObjectFactory ⼯⼚存⼊三级缓存。⾄此,三级缓存中同时存在 BeanA 和 BeanB 的⼯⼚,它们都代表未完成初始化的半成品。
第三步: BeanB 属性注⼊时发现循环依赖。
当Spring 试图填充 BeanB 的属性时,检测到它需要注⼊ BeanA 。此时容器启动依赖查找:
在⼀级缓存(存放完整Bean )中未找到 BeanA ;
在⼆级缓存(存放已暴露的早期引⽤)中同样未命中;
最终在三级缓存中定位到 BeanA 的⼯⼚。
Spring ⽴即调⽤该⼯⼚的 getObject() ⽅法。这个⽅法会执⾏关键决策:若 BeanA 需要AOP 代理,则动 态⽣成代理对象(即使 BeanA 还未初始化);若⽆需代理,则直接返回原始对象。得到的这个早期引⽤(可能是代理)被放⼊⼆级缓存( earlySingletonObjects ),同时从三 级缓存清理⼯⼚条⽬。最后,Spring 将这个早期引⽤注⼊到 BeanB 的属性中。⾄此, BeanB 成功持有 BeanA 的引⽤—— 尽管 BeanA 此时仍是个半成品。
第四步:完成 BeanB 的⽣命周 期。
BeanB 获得所有依赖后,Spring 执⾏其初始化⽅法(如 @PostConstruct ),将其转化为完整可⽤的Bean 。随后, BeanB 被提升⾄⼀级缓存( singletonObjects ),⼆级和三级缓存中关于 BeanB 的临时条⽬均被清除。此时 BeanB 已准备就绪,可被其他对象使⽤。
第五步:回溯完成 BeanA 的构建。
随着 BeanB 创建完毕,流程回溯到最初中断的 BeanA 属性注⼊环节。Spring 将已完备的 BeanB 实例注⼊ BeanA ,接着执⾏ BeanA 的初始化⽅法。这⾥有个精妙细节:若之前为 BeanA ⽣成过早期代理,Spring 会直接复⽤⼆级缓存中的代理对象作为最终Bean ,⽽⾮重复创建。最终,完全初
始化的 BeanA (可能是原始对象或代理)⼊驻⼀级缓存,其早期引⽤从⼆级缓存移除。⾄此循环
闭环完成,两个 Bean 皆可⽤。
三级缓存的设计 的精髓:
三级缓存⼯⼚( singletonFactories )负责 在实例化后⽴刻暴露对象⽣成能⼒,兼顾AOP 代理
的提前⽣成;
⼆级缓存( earlySingletonObjects )临时存储已确定的早期引⽤,避免重复⽣成代理;
⼀级缓存( singletonObjects )最终交付 完整Bean 。
整个机制通过中断初始化流程、逆向注⼊半成品、延迟代理⽣成三⼤策略,将循环依赖的死结转
化为有序的接⼒协作。
值得注意的是,此⽅案仅适⽤于Setter/Field 注⼊的单例Bean ;构造器注⼊因必须在实例化前获得
依赖,仍会导致⽆解的死锁。
Java 21 新特性知道哪些?
新新 语⾔特性:
Switch 语句的模式匹配:该功能在 Java 21 中也 得到了增强。它允许在 switch 的 case 标签中
使⽤模式匹配,使操作更加灵活和类型安全,减少了样板代码和潜在错误。例如,对于不 同类
型的账⼾类,可以在 switch 语句中直接根据账⼾类型的模式来获取相应的余额,如 case
savingsAccount sa -> result = sa.getSavings();数组模式:将模式匹配扩展到数组中,使开发者能够在条件语句中更⾼效地解构和检查数组内
容。例如, if (arr instanceof int[] {1, 2, 3}) ,可以直接判断数 组 arr 是否匹配指定的模式。
字符串模板(预览版):提供了⼀种更可读、更易维护的⽅式来构 建复杂字符串,⽀持在字符串
字⾯量中直接嵌⼊表达式。例如,以前可能需要使⽤ "hello " + name + ", welcome to the
geeksforgeeks!" 这样的⽅式来拼接 字符串,在 Java 21 中可以使 ⽤ hello {name}, welcome tothe geeksforgeeks! 这种更简洁的写法
新并发特性⽅⾯:
虚拟线程:这是 Java 21 引⼊的⼀种轻量级并发的新选择。它通过共享堆栈的⽅式,⼤⼤降低
了内存消耗,同时提⾼了应⽤程序的吞吐 量和响 应速度。可以使 ⽤静态构建⽅法、构建器或
来创建和使⽤虚拟线程。
Scoped Values (范围值):提供了⼀种在线程间共享不 可变数据的新⽅式,避免使⽤传统的线
程局部存储,促进了更好的封装性和线程安全,可⽤于在不通过⽅法参数传递的情况下,传递
上下 ⽂信息,如⽤⼾会话或配置设置。
SpringBoot 的核⼼注解有哪些?
Bean 相关:
@Component :将⼀个类标识为 Spring 组件(Bean ),可以被 Spring 容器⾃动检测和注册。通⽤注解,适⽤于任何 层次的组件。
@ComponentScan :⾃动扫描指 定包及 其⼦包中的 Spring 组件。
@Controller :标识控制层组件,实际上是 @Component 的⼀个特化,⽤于表⽰ Web 控制器。处理 HTTP 请求并返回视图或响应数据。
@RestController :是 @Controller 和 @ResponseBody 的结合,返回的对象会⾃动序列化为JSON 或 XML ,并写⼊ HTTP 响应体中。
@Repository :标识持久层组件(DAO 层),实际上是 @Component 的⼀个特化,⽤于表⽰数据访问组件。常⽤于与 数据库交互 。
@Bean :⽅法注 解,⽤于修饰⽅法,主要功能是将修饰⽅法的返回对象添加到 Spring 容器中,使得其他组件可以通过依赖注⼊的⽅式使⽤这个对象。
依赖注⼊:
@Autowired :⽤于⾃动注⼊依赖对象,Spring 框架提供的注解。
@Resource :按名称⾃动注⼊依赖对象(也可以按类型,但默认按名称),JDK 提供注解。
@Qualifier :与 @Autowired ⼀起使⽤,⽤于指定要注⼊的 Bean 的名称。当存在多个相同类型的 Bean 时,可以使 ⽤ @Qualifier 来指定注⼊哪⼀个。
读取配置:
@Value :⽤于注⼊属性值,通常从配置⽂件中获取。标注在字段上,并指定属性值的来源(如配置⽂件中的某个属性)。
@ConfigurationProperties :⽤于将配置属性绑定到⼀个实体类上。通常⽤于从 配置⽂件中读取属性值并绑定到类的字段上。
Web 相关:
@RequestMapping :⽤于映射 HTTP 请求到处理⽅法上,⽀持 GET 、POST 、PUT 、DELETE 等请求⽅法。可以标注在类或⽅法上。标注在类上时,表⽰类中的所有响应请求的⽅法都是以该
类路径为⽗路径。
@GetMapping 、@PostMapping 、@PutMapping 、@DeleteMapping :分别 ⽤于映射 HTTP GET 、POST 、PUT 、DELETE 请求到处理⽅法上。它们是 @RequestMapping 的特化,分别 对应不同的 HTTP 请求⽅法。
其他常⽤注解:
@Transactional :声明事务管理。标注在类或⽅法上,指定事务的传播⾏为、隔离级别等。
@Scheduled :声明⼀个⽅法需要定时执⾏。标注在⽅法上,并指定定 时执⾏的规则(如每隔⼀定时间执⾏⼀次)。
场景
⾼并发的场景下保证数据库和缓存⼀致性?
对于读数据,我会选择旁路缓存策略,如果 cache 不命中,会从 db 加载数据到 cache 。对于写数
据,我会选择更新 db 后,再删除缓存。

缓存是通过牺牲 强⼀致性来提⾼性能的。这是由CAP 理论决定的。缓存系统适⽤的场景就是⾮强⼀
致性的场景,它属于CAP 中的AP 。所以,如果需要数据库和缓存数据保持强⼀致,就不适合使⽤
缓存。
所以使 ⽤缓存提升性能,就是会有数据更新的延迟。这需要我们在设计 时结合业务仔细思考是否
适合⽤缓存。然后缓存⼀定要设置过期时间,这个时间太短、或者太⻓都不好:
太短的话请求可能会⽐较多的落到数据库上,这也意味着失去了缓存的优势。
太⻓的话缓存中的脏数据会使 系统⻓时间处于⼀个延迟的状态,⽽且系统中⻓时间没有⼈访问
的数据⼀直存在内存中不 过期,浪费内存。
但是,通过⼀些⽅案优化处理,是可以最终⼀致性的。
针对删除缓存异常的情况,可以使 ⽤ 2 个⽅案避免:
删除缓存重试策略(消息队列)
订阅 binlog ,再删除缓存(Canal+ 消息队列)
消息队列⽅案
我们可以引⼊消息队列,将第⼆个操作(删除缓存)要操作的数据加⼊到消息队列,由消费者来
操作数据。
如果应⽤删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试
机制。当然,如果重试超过的⼀定次数,还是没有成功,我们就需要向业务层发送报错信息
了。
如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个 例⼦,来说明重试机制的过程。

重试删除缓存机制还可以,就是会造成好多 业务代码⼊侵。
订阅 MySQL binlog ,再操作缓存
「先更新数 据库,再删缓存」的策略的第⼀步是更新数 据库,那么更新数 据库成功,就会产⽣⼀
条变更⽇志,记录在 binlog ⾥。
于是我们就可以通过订阅 binlog ⽇志,拿到具体要操作的数据,然后再执⾏缓存删除,阿⾥巴巴
开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从 复制的交互 协议,把⾃⼰伪装成⼀个 MySQL 的从节点,向 MySQL 主节点
发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal ,Canal 解析 Binlog 字节流
之后,转换为便于读取的结构化数据,供下游程序订阅使⽤。
下图是 Canal 的⼯作原理:

将binlog ⽇志采集发送到MQ 队列⾥⾯,然后编写⼀个简单的缓存删除消息者订阅binlog ⽇志,根
据更新log 删除缓存,并且通过ACK 机制确认处理这条更 新log ,保证数据缓存⼀致性
使⽤消息队列还应该注意哪些问题?
需要考虑消息可靠性和顺序性⽅⾯的问题。
消息队列的可靠性、顺序性怎 么保证?
消息可靠性可以通过下⾯这些⽅式来保证
消息持久化:确保消息队列能够持久化消息是⾮常关键的。在系统崩溃、重启或者⽹络故障等
情况下,未处理的消息不应丢失。例如,像 RabbitMQ 可以通过配置将消息持久化到磁盘,通
过将队列和消息都设置为持久化的⽅式(设置 durable = true ),这样在服务器重启后 ,消息依然可以被重新读取和处理。
消息确认机制:消费者在成功处理消息后,应该向消息队列发送确认(acknowledgment )。消
息队列只有收到确认后,才会将消息从队列中移除。如果没有收到确认,消息队列可能会在⼀
定时间后重新发送消息给其他消费者或者再次发送给同⼀个消费者。以 Kafka 为例,消费者通
过 commitSync 或者 commitAsync ⽅法来提交偏移量(offset ),从⽽确认消息的消费。
消息重试策略:当消费者处理消息失败时,需要有合理的重试策略。可以设置重试次数和重试
间隔 时间。例如,在第⼀次处理失败后,等待⼀段时间(如 5 秒)后进⾏第⼆次重试,如果重
试多次(如 3 次)后仍然失败,可以将消息发送到死信队列,以便 后续⼈⼯排查或者采取其他
特殊处理。
消息顺序性保证的⽅式如下:
有序消息处理场景识别:⾸先需要明确业务场景中哪些消息是需要保证顺序的。例如,在⾦融
交易系统中,对于同⽤⼾的转账操作顺序是不能打乱的。对于需要顺序处理的消息,要确保消
息队列和消费者能够按照特定的顺序进⾏处理。
消息队列对顺序性的⽀持:部分消息队列本⾝提供了顺序性保证的功能。⽐如 Kafka 可以通过
将消息划分到 同⼀个分区(Partition )来保证消息在分区内是有序的,消费者按照分区顺序读取
消息就可以保 证消息顺序。但这也可能会限制消息的并⾏处理程度,需要在顺序性和吞吐 量之
间进⾏权衡。
消费者顺序处理策略:消费者在处理顺序消息时,应该避免并发处理可能导致顺序打乱的情
况。例如,可以通过单线程或者使⽤线程池并对顺序消息进⾏串⾏化处理等⽅式,确保消息按
照正确的顺序被消费。
系统设计
秒杀系统设计 如何做?
系统架构 分层设计 如下。
前端层:
⻚⾯静态化:将商品展⽰⻚⾯等静态内容进⾏缓存,⽤⼾请求时可以直接从缓存中获取,减少
服务器的渲染压⼒。例如,使⽤内容分发⽹络(CDN )缓存商品图⽚、详情介绍等静态资源。
防刷机制:通过验证码、限制⽤⼾请求频率等⽅式防⽌恶意刷请求。例如,在秒杀开始前要求
⽤⼾输⼊验证码,并且在⼀定时间内限制单个⽤⼾的请求次数,如每秒最多允许 3 次请求。
应⽤层:
负载均衡:采⽤负载均衡器将⽤⼾请求均匀地分配到多个后端服务器, 避免单点服务器过载 。
如使⽤ Nginx 作为负载均衡器, 根据服务器的负载情况和性能动态分配请求。
服务拆分与微服务化:将秒杀系统的不同功能模块拆分成独⽴的微服务,如⽤⼾服务、商品服
务、订单服务等。这样可以独⽴部署和扩展各个模块,提⾼系统的灵活性和可 维护性。
缓存策略:在应⽤层使⽤缓存来提⾼系统性能。例如,使⽤ Redis 缓存商品库存信息,⽤⼾下
单前先从 Redis 中查询库存,减少对 数据库的直接访问。
数据层:
数据库优化:对数据库进⾏性能优化,如数据库索引优化、SQL 语句优化等。对于库存表,可
以为库存字 段添加索引,加快库存查询和更新的速度。
数据库集群与读写分离:采⽤数据库集群来提⾼数据库的处理能⼒,同时进⾏读写分离。将读
操作(如查询商品信息)和写操作(如库存扣减、订单⽣成)分布到不同的数据库节点上,提
⾼系统的并发处理能⼒。
⾼并发场景下扣减库存的⽅式:
预扣库存:在⽤⼾下单时,先预扣库存,将库存数量在缓存(如 Redis )中进⾏减 1 操作。同时
设置⼀个较短的过期时间,如 1 - 2 分钟。如果⽤⼾在过期时间内完成⽀付,正式扣减库存;如
果未 完成⽀付,库存⾃动回补。
异步更新数 据库:通过 Redis 判断之后,去更新数 据库的请求都是必要的请求,这些请求数据
库必须要处理,但是如果数据库还是处理不过来这些请求怎么办呢?这个时候就可以考虑削峰
填⾕操作了,削峰填⾕最好的实践就是 MQ 了。经过 Redis 库存扣减判断之后,我们已经确保
这次请求需要⽣成订单,我们就可以通过异步的形式 通知订单服务⽣成订单并扣减库存。
数据库乐观锁防⽌超卖:更新数 据库减库存的时候,采⽤乐观锁⽅式,进⾏库存限制条件,
update goods set stock = stock - 1 where goods_id = ? and stock >0